ANÁLISE DE ASSINATURAS MANUSCRITAS BASEADA NOS PRINCÍPIOS DA GRAFOSCOPIA
Prevenção de Fraudes
1 A biometria
biometria é a utilização de características biológicas (face, íris, impressão digital) ou tratamento comportamental (assinatura e voz) para a verificação da identidade do indivíduo. Autenticação biométrica é entendida como uma alternativa, mais confiável, aos sistemas de segurança baseados em senha, pois é relativamente difícil de ser falsificada, roubada ou obtida. Em particular, a assinatura está relacionada ao comportamento biométrico: ela não é baseada em propriedades físicas, tal como a impressão digital ou a face de um indivíduo, mas apenas em características comportamentais [KHOLMATOV, 2003].
A assinatura constitui atualmente, no contexto jurídico, um dos meios para comprovar a intenção em transações envolvendo documentos [JUSTINO, 2002], ou seja, quando se assina qualquer documento, este ato representa a aceitação dos fatos, indicando a sua concordância. Esta premissa garante a utilização de assinaturas como recurso comprobatório em contratos, escrituras e cheques bancários, entre outros, pois representa uma marca ou selo pessoal do indivíduo.
Diversos tipos de documentos precisam ser assinados. Desta forma, técnicas confiáveis para verificação de assinaturas são requisitadas. Mesmo que a maioria das recentes pesquisas estejam focadas em assinaturas digitais de documentos eletrônicos (isto é, um código de chave codificado associado com um documento em sua versão eletrônica, especialmente projetado para evitar manipulação por pessoas não autorizadas), um grande número de documentos de papel assinados ainda é produzido diariamente [SANSONE & VENTO, 2000], tais como os cheques bancários.
Não se pode negar que o uso de cartões de créditos cresceu muito nos últimos anos em relação aos cheques bancários. Porém para cada transação eletrônica existem duas envolvendo cheques, principalmente, devido ao uso do cheque pré-datado (versão brasileira do capitalismo). Além disso, muitos comerciantes usam os cheques recebidos dos clientes como moeda, assim escapando de pagamentos de taxas bancárias [SILVA, 2003], o que garante a aplicação do sistema proposto e a continuidade do uso de assinaturas neste tipo de documento, podendo ser usado também em recibos de cartão de crédito.
Muitas vezes, pelo fato de estar sujeita a uma análise subjetiva, que pode gerar discordâncias, a detecção de autenticidade de assinaturas constitui-se em uma tarefa complexa, pois a verificação manual para uma grande quantia de documentos é tediosa e facilmente influenciada por fatores físicos e psicológicos [XIAO & LEEDHAM, 1999]. No campo computacional, a verificação de assinaturas estáticas continua sendo um problema em aberto, não existindo um método totalmente aceito. Uma abordagem que incorpore a visão subjetiva de forma satisfatória, certamente encontrará aplicações práticas, principalmente no que diz respeito a sistemas de automação bancária e comercial.
Atualmente, com recursos computacionais mais eficazes, tarefas que há alguns anos pareciam inviáveis agora atraem novas pesquisas. Dentro deste contexto, a verificação de assinaturas é uma importante e desafiadora área de estudos na qual buscam-se soluções computacionais automatizadas relacionadas à autenticação, procurando estabelecer uma comparação segura entre um modelo de assinatura conhecido com um outro questionado. O uso da análise grafotécnica pericial utilizada em ciências forenses representa um nicho de pesquisa que se encaixa perfeitamente na verificação de assinaturas manuscritas. Desta forma, os critérios técnicos dos peritos são empregados na análise das características da escrita, as quais podem ser conscientes ou inconscientes, como também na decisão da autenticidade.
Desafio
A abordagem proposta tem como desafio minimizar a complexidade que envolve alguns fatores relacionados à escrita da assinatura, como a variação intrapessoal, ilustrada na Figura 1.1(b), que decorre da instabilidade que existe entre assinaturas do mesmo autor. A assinatura de uma pessoa pode mudar ao longo do tempo devido a diversos fatores como o estado psicológico do autor ou a mudança do dispositivo de entrada [XIAO & LEEDHAM, 1999]. Outro fator de complexidade é a similaridade interpessoal, conforme ilustrada na Figura 1.2 que representa a semelhança entre assinaturas de autores distintos.

Alguns aspectos ligados à variação de escrita podem estar relacionados ao alfabeto, à forma de escrita de determinada região, condição social, país, estado físico ou mental e idade cronológica da população analisada [CHA, 2001]. Assinar não é um processo perfeitamente preciso com dados de características idênticas. A única certeza é que quando duas assinaturas são exatamente idênticas, uma delas é provavelmente uma cópia [RASHA, 1994]. Assinaturas, por representarem um caso especial de manuscritos, podem ser divididas nas categorias, cursivas ou rubricas, estas contendo caracteres especiais, distorcidos ou ainda uma representação simbólica, tais como desenhos estilizados. Neste caso, uma análise não contextual é necessária, pois não existe a interpretação de texto durante a verificação, conforme Sabourin e Genest [SABOURIN & GENEST, 1994], o que representa outro fator de complexidade.
As assinaturas podem ainda sofrer ações fraudulentas, sendo classificadas por peritos em documentos questionados quanto à sua autenticidade em genuína e não genuína [JUSTINO, 2002]. O uso da palavra falsificação é um termo legal que deve ser cuidadosamente usado nas conclusões apresentadas pelo perito em documentos questionados [JUSTINO, 2001]. Falsificações podem ser bastante diferentes de assinaturas genuínas tanto em aparência como em suas características, ou podem ser tão similares que mesmo peritos sentem dificuldades em distingui-las corretamente [XIAO & LEEDHAM, 1999], desta forma dificultando a aplicação de sistemas computacionais na verificação de assinaturas [JUSTINO et al., 2003].
As assinaturas não genuínas, ou falsificações, normalmente podem ser classificadas em duas categorias: simples ou habilidosa conforme Faez [FAEZ et al., 1997]. Justino [JUSTINO, 2001] define uma terceira categoria, a aleatória, que é ilustrada na Figura 1.3 juntamente com os demais tipos. Estas categorias são definidas como:
• Simples: o falsificador simplesmente escreve o nome do autor, que pode ser semelhante ou não à original;
• Servil, simulada ou habilidosa: o falsificador simula uma assinatura genuína usando um modelo como referência, tentando chegar o mais próximo possível de seu traçado original;
• Aleatórias: o falsificador inventa uma assinatura ou utiliza a sua própria, a qual não possui semelhanças com a genuína.

No processo que envolve a verificação automática de assinaturas o objetivo é discriminar entre uma assinatura genuína e todos os tipos de falsificações. Portanto, dadas duas classes w1, representando a classe de assinaturas genuínas de um autor e w2, representando a classe de assinaturas não genuínas, o desafio é basicamente separá-las. Porém, quando falsificações são submetidas ao sistema, principalmente as simuladas, a complexidade aumenta. Se um limiar de decisão puder ser definido, a classificação consiste em determinar em qual lado do limite qualquer novo dado deve se situar. A função matemática de tal limite de decisão é uma função discriminante, sendo que achá-la geralmente não é trivial. Por esta razão, em um processo de aprendizagem algumas amostras de falsificações são identificadas erroneamente como pertencendo à classe w1, o que pode acontecer até mesmo com amostras de falsificações simples [JUSTINO et al., 2003], conforme a Figura 1.4.
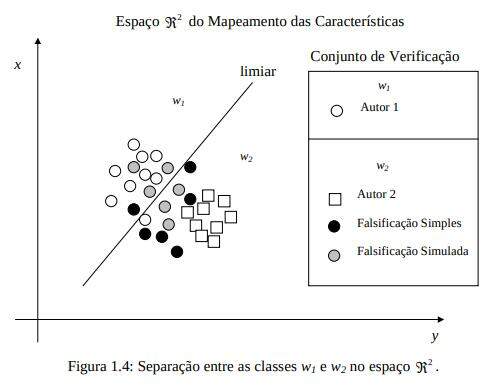
Em situações práticas a classe w2, que representa a classe de amostras não genuínas pode englobar os vários tipos de falsificações (simples, simuladas e aleatórias). As falsificações aleatórias são representadas por amostras de assinaturas genuínas que pertencem a um autor diferente.
Motivação
O direcionamento da abordagem proposta está baseado nos preceitos do grafismo, apresentados inicialmente por Chuang [CHUANG, 1977] e mais recentemente por Justino [JUSTINO, 2001], nos quais os subsídios e a visão que o perito grafotécnico possui para a resolução de problemas criminais são transcritos na extração das características.O número de espécimes utilizado em qualquer abordagem relacionado ao reconhecimento de manuscritos que envolve treinamento de classificadores torna-se um problema quando transposto para sistemas práticos, em aplicações bancárias ou comerciais, que dispõem em geral de um número reduzido de amostras de cada classe, autor ou indivíduo. É inviável, então, solicitar diversas vezes aos usuários a produção de assinaturas para o sistema empregado (manual ou automatizado). Desta forma uma abordagem alternativa validada estatisticamente faz-se necessário, para um método ser aceito cientificamente e também para a sua utilização prática.
Atualmente métodos baseados em modelos pessoais [HUANG & YAN, 1997] [SABOURIN & GENEST, 1994], são geralmente adotados como solução nesta área. Entretanto, em aplicações reais existe, em geral um número bastante limitado de amostras que podem ser usados no treinamento de modelos pessoais (em torno de 4 a 6), o que inviabiliza a maioria destas abordagens, apesar de apresentarem excelentes resultados [JUSTINO et al., 2003]. Além da motivação prática, existe também o interesse despertado pelo caráter desafiador da área de pesquisa. A área de reconhecimento de padrões possui técnicas que são aplicadas na solução de problemas reais cujo comportamento não obedece aos princípios rígidos da lógica. Estes são alguns dos motivos que despertam o interesse nesta abordagem científica.
Proposta
A proposta deste trabalho é apresentar uma abordagem de verificação de assinaturas estáticas, com o objetivo de autenticar a assinatura de um escritor, ao contrário do reconhecimento de assinaturas no qual o objetivo é determinar quem é o autor da assinatura [CAVALCANTI et al., 2002]. Dentro deste contexto as seguintes metas são propostas:
• Minimizar a complexidade que envolve todas as etapas de um sistema de verificação de assinaturas;
• Reduzir o número de amostras genuínas por autor na produção de um modelo, simulando ambientes de aplicações não automatizadas, e somente o uso a priori de falsificações aleatórias;
• Utilização dos preceitos da grafoscopia na análise das características da escrita [JUSTINO, 2001] como alternativa para o problema proposto;
• Obter uma metodologia que reduza o número de modelos associados à autenticação de assinaturas.
Contribuições
Nesta subseção apresentam-se as contribuições deste trabalho de pesquisa as quais são:
• Uma alternativa para o número excessivo de assinaturas genuínas por autor. Problema este encontrado na maioria das abordagens relacionadas à verificação de assinaturas [JUSTINO, 2001], [HUANG & YAN, 1997];
• O uso de uma abordagem genérica que utiliza somente um único treinamento em todo o processo, independente do autor ou assinatura analisada; • A implementação computacional dos princípios da grafoscopia tanto na extração das características quanto no processo de decisão.
Organização da Dissertação
Esta dissertação está organizada em sete capítulos. O primeiro contém uma introdução sobre verificação automática de assinaturas manuscritas. No segundo capítulo é apresentada uma fundamentação teórica de classificadores para verificação de assinaturas. No terceiro capítulo apresenta-se o resumo do estado da arte na autenticação das assinaturas. No quarto capítulo é elucidada a metodologia. No quinto as etapas da abordagem proposta. Os experimentos realizados neste trabalho para validar estatisticamente o método são mostrados no sexto capítulo. E finalmente no sétimo capítulo são apresentadas as conclusões e propostas para trabalhos futuros.
2 Fundamentação Teórica
te capítulo apresenta uma base teórica dos processos de autenticação de assinaturas, contendo uma breve descrição de reconhecimento de padrões, tipos e métodos de abordagens relacionados ao problema. Também são apresentados os classificadores abordados, com um estudo de redes neurais, em específico redes MLP e dicas de configuração de parâmetros das mesmas. Ao final, é apresentada uma introdução do classificador SVM.
Reconhecimento de Padrões
Um padrão é uma descrição de um objeto que pode ser um conjunto de medidas ou observações normalmente representadas através de um vetor ou notação de matriz [RASHA, 1994]. No processo de verificação de assinaturas, uma assinatura é um exemplo de padrão que pode ser representado por uma matriz de pixels. O reconhecimento de padrões pode ser definido como a categorização de dados de entrada em classes identificáveis, via extração de características significantes ou atributos de detalhes relevantes. Conseqüentemente o objetivo fundamental do reconhecimento de padrões é a classificação. Um sistema de reconhecimento de padrões básico divide-se em duas fases. A primeira é a extração das características e a segunda a classificação [RASHA, 1994]. Características são quaisquer medidas extraíveis de um padrão que podem contribuir para a classificação, sendo que as mesmas podem ser representadas por valores contínuos ou discretos.
Na distinção entre diferentes classes, muitas características são requisitadas. Selecionar estas características pode ser uma difícil tarefa que exigirá significantes esforços computacionais. A seleção de características é o processo inicial para o reconhecimento de padrões, que envolve geralmente um julgamento, ou seja, os descritores de uma assinatura devem conter informações representativas da classe a que ela pertence de modo a permitir diferi-la de falsificações [MARAR et al., 2002].
A chave é escolher e extrair características que [RASHA, 1994]:
• Sejam computacionalmente possíveis;
• Conduzam a um sistema com poucos erros de má-classificação;
• Reduzam a quantia de informação manipulada, sem perda de desempenho.
Satisfazendo estes critérios na extração de características, ocorre o processo de treinamento, durante o qual apresenta-se repetidamente ao classificador um conjunto de padrões de entrada juntamente com a categoria à qual cada padrão apresentado pertence. Posteriormente, na etapa de testes apresenta-se um novo padrão que pertence à mesma população de padrões utilizada no treinamento. O classificador deve ser capaz de identificar a classe daquele padrão particular, pela informação que ele extraiu dos dados de treinamento. A fase de aprendizado é uma etapa muito importante do sistema de verificação. Se realizada adequadamente os modelos oriundos dessa fase possuem um conjunto rico de informações que permitem uma boa precisão do processo de verificação. Esta etapa possibilita a eliminação de redundâncias, o que por sua vez, propicia uma redução do tempo gasto no processo de decisão.
De acordo com Haykin [HAYKIN, 2001], os seres humanos têm habilidades inerentes ao reconhecimento de padrões, pois recebem dados do mundo a sua volta através dos sentidos e são capazes de reconhecer a fonte dos dados, quase que imediatamente e sem esforço. Eles podem, por exemplo, reconhecer um rosto familiar de uma pessoa, muito embora esta pessoa tenha envelhecido. Em termos conceituais, Haykin [HAYKIN, 2001] define que um padrão é representado por um conjunto de m observações, que pode ser visto como um ponto x de um espaço de observações (de dados) m-dimensional. A extração de características é descrita por uma transformação que mapeia o ponto x para um ponto intermediário y no espaço de características q-dimensional, com q < m, como indicado na Figura 2.1.
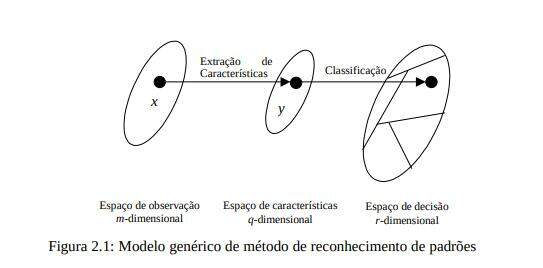
Esta transformação pode ser vista como uma redução de dimensionalidade (compressão de dados), cuja utilização é justificada por simplificar a tarefa de classificação. A própria classificação é descrita como uma transformação que mapeia o ponto intermediário y para uma das classes em um espaço de decisão r-dimensional, em que r é o número de classes a ser distinguida.
Tipos de Abordagens na Verificação de Assinaturas
As abordagens relacionadas à verificação automática de assinaturas estão diretamente ligadas ao mecanismo de aquisição de dados. Se o processo de verificação ocorre no mesmo tempo em que a assinatura é escrita, o método é dito on-line ou dinâmico, neste caso há necessidade de um dispositivo de acesso especial para processamento quando a assinatura é produzida. Quando as informações são inicialmente adquiridas provavelmente de uma folha de papel por um digitalizador ou câmera para posterior análise da imagem, o método é dito off-line ou estático. A tarefa de verificação em sistemas off-line torna-se mais complexa que em on-line, principalmente pela quantidade de informações disponíveis [CAVALCANTI et al., 2002].
Os métodos estáticos apresentam duas classes de características extraídas da imagem de acordo com Justino [JUSTINO, 2001]. A classe primeira é chamada de estática, porque possui a capacidade de representar as características relacionadas à forma, como por exemplo, o comprimento e a altura máxima de uma assinatura. A segunda classe chamada de pneumodinâmica, possui a capacidade de representar as características dinâmicas da escrita como tensão do traçado, inclinação e pressão. Métodos baseados em características estáticas são usados geralmente para identificar falsificações simples e aleatórias. A razão é que estes métodos mostram-se mais aptos para descrever características relacionadas à forma da assinatura. Já as abordagens pseudodinâmicas são capazes de capturar detalhes da movimentação da escrita, sendo portanto mais adequados para identificar falsificações habilidosas.
A abordagem usada para manipular características em uma imagem determina a eficiência de um método na resolução do problema. De acordo com Justino [JUSTINO, 2001] tais métodos podem ser:
• Globais: os quais usam as características gerais da imagem, sendo mais insensíveis às variações intrapessoais, porém com menor capacidade de distinção de falsificações simuladas;
• Locais: dependem de um processo de segmentação da imagem em partes a serem analisadas, descrevendo a particularidade do traçado e sendo mais eficientes na identificação de todos os tipos de falsificações.
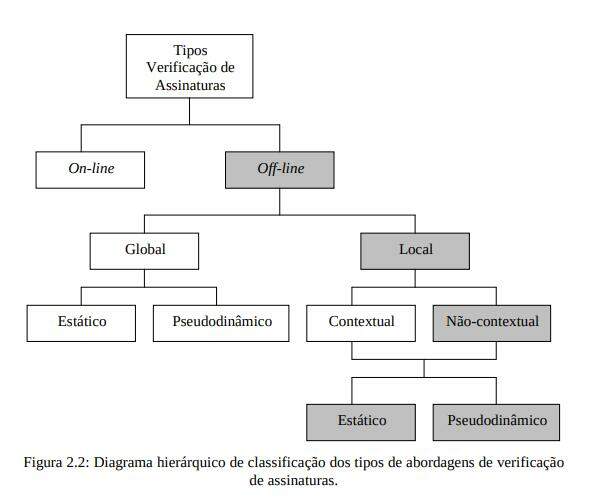
A imagem de uma assinatura é basicamente uma coleção de pontos distribuídos sobre uma área bem definida e possuindo formas distintas. As características globais, que podem capturar a natureza da distribuição destes pontos no espaço, são idealmente desejáveis para aspectos mais grosseiros da assinatura. Estas características não são capazes de capturar aspectos estruturais das imagens das assinaturas, essenciais para a detecção de traços de falsificações ou fotocópias, mas possuem poder suficiente para discriminar e eliminar erros de substituição [BAJAJ & CHAUDHURY, 1996]. O diagrama hierárquico da Figura 2.2 demonstra a classificação dos métodos de verificação automática de assinaturas, destacando os que fazem parte da abordagem proposta.
Métodos de Verificação
A escolha do tipo de representação (os tipos de primitivas) constitui uma etapa essencial na elaboração de um método de verificação. As dificuldades surgem principalmente em relação à maneira como são tratadas as entidades naturais usadas para obter a descrição matemática, induzida por um método teórico formal. Essa indução possui dois reflexos: o dimensionamento do espaço representativo do fenômeno, que deve possuir propriedades para facilitar o processo de decisão, e a obtenção de um espaço de representação que permita uma implementação computacional [JUSTINO, 2001]. Os dois tipos de métodos formais mais comuns são:
• Métodos estruturais: buscam descrever informações geométricas de maneira estrutural, representando formas complexas a partir de componentes elementares, chamadas primitivas. Os métodos estruturais distinguem-se basicamente em dois grupos [JUSTINO, 2001]:
- Métodos estruturais propriamente ditos: a estrutura utilizada é um grafo que permite representar as formas, ou seja, as primitivas e as relações entre elas. A fase de decisão consiste na comparação do grafo representativo da forma do modelo com o grafo da forma em teste;
- Métodos sintáticos: a estrutura é usada para codificar a forma em uma lista, utilizando um alfabeto cujos componentes representam elementos da forma a descrever. A fase de decisão consiste na análise da lista com a ajuda de regras sintáticas, como as utilizadas em um texto escrito em uma linguagem natural.
• Métodos estatísticos: consistem em efetuar as medições do espaço métrico através da estatística. O aprendizado é executado através da separação de um conjunto de amostras em classes obedecendo a um conjunto de características comuns. A modelagem estatística se beneficia dos processos automáticos. Os principais métodos estatísticos são os paramétricos e os não- paramétricos [JUSTINO, 2001]:
- Paramétricos, trabalham com a hipótese de que as classes possuem uma distribuição de probabilidade com comportamento determinado. O método supõe o conhecimento prévio das leis que regem as probabilidades das classes envolvidas e ainda que seus parâmetros de estimação possuem normalmente um comportamento gaussiano. Esses métodos exigem uma base de dados de aprendizado para uma correta estimação dos parâmetros;
- Não-paramétricos, assumem que as leis de formação da probabilidade de uma classe são desconhecidas. O problema consiste em propor algoritmos de convergência que determinem o limiar ideal de decisão.
Mais recentemente a neuro computação, mais especificamente as redes neurais artificiais, tem sido reconhecida como um método para resolver problemas de reconhecimento de padrões [RASHA, 1994]. A computação neural surgiu da necessidade de entender como os sistemas neurais biológicos armazenavam e manipulavam a informação. É importante destacar que uma rede neural é capaz de aprender as características estatísticas do ambiente no qual ela opera, desde que os dados utilizados para o seu aprendizado sejam suficientemente representativos do ambiente.
De acordo com Haykin [HAYKIN, 2001], o reconhecimento de padrões realizado por uma rede neural é de natureza estatística. Os padrões são representados por pontos em um espaço de decisão multidimensional, dividido em regiões, cada uma associada a uma classe. As fronteiras de decisão são determinadas pelo processo de treinamento e sua construção torna-se estatística pela variação inerente que existe dentro das classes e entre as mesmas. As redes neurais são capazes de estimar as probabilidades a posteriori, das quais provêm a base para estabelecer regras de classificação e análise de desempenho estatístico [ZHANG, 2000].
Teoria da Classificação Bayesiana
Esta teoria é a base dos métodos de classificação estatística. Ela provê o modelo de probabilidade fundamental para os procedimentos de classificação, como a análise discriminante estatística [ZHANG, 2000]. Considera-se um problema geral de classificação de M grupos no qual cada objeto tem um vetor de atributos x de dimensão d, em que w denota a variável membro que toma um valor wj se um objeto é pertencente à classe j. Define-se P(wj) como a probabilidade a priori da classe j e f(x|wj) como a função densidade de probabilidade. De acordo com a regra de Bayes:

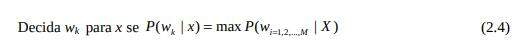
A interpretação das saídas de redes neurais como probabilidades Bayesiana permite que as saídas de múltiplas redes possam ser combinadas para melhorar o nível de decisão, simplificando a criação de limiares de rejeição, desde que certas condições sejam satisfeitas:
• Hajam elementos de processamentos suficientes para realizar o mapeamento;
• Hajam dados em quantidade e qualidade;
• A aprendizagem convirja para o máximo global;
• As saídas estejam entre 0 e 1 com ∑= 1.
Classificadores estatísticos são baseados na teoria de decisão de Bayes, e o fato de que redes neurais podem prover estimativas de probabilidades a posteriori implicitamente estabelecem uma ligação entre redes neurais e classificadores estatísticos. A direta comparação entre eles pode não ser possível porque as redes neurais são métodos de modelos livres não-lineares enquanto que os métodos estatísticos são basicamente lineares e baseados no modelo, de acordo com Zhang [ZHANG, 2000]. Através da codificação apropriada dos valores de saída a rede neural pode modelar diretamente algumas funções discriminantes. Assim, o vetor de característica de entrada é mapeado em um valor associado com uma classe particular. Por exemplo, em um problema de classificação binária, a saída desejada é codificada como 1 sendo o dado da classe w1 e –1 se ele é da classe w2. Então a rede neural estima a seguinte função discriminante g(x) [DUDA & HART, 1973]:

A regra discriminante é simples: associar x para w1 se g(x) > 0 ou para w2 se g(x) < 0. Qualquer aumento na função de probabilidade a posteriori pode ser usado para alterar a equação (2.5) para formar uma função discriminante diferente, mas essencialmente é a mesma regra de classificação.
Teoria de Decisão Bayesiana
De acordo com Fumera [FUMERA et al., 2000], um classificador N-classes é apontado para subdividir o espaço de características em N regiões de decisão Di , i = 1,...,N, tal que os padrões da classe wi pertencem à região Di . Conforme a teoria de reconhecimento de padrões estatísticos, tal região de decisão é definida para maximizar a probabilidade do correto reconhecimento, ou seja, a precisão do classificador, e conseqüentemente minimizar a probabilidade do erro do classificador. Para este fim, a regra de decisão de Bayes associa a cada padrão x a classe para a qual a probabilidade a posteriori P(wi|x) é máxima. Uma otimização da probabilidade da taxa de erro provida pela regra de Bayes pode ser obtida usando a opção de rejeição, de acordo com Fumera [FUMERA et al., 2000]. Neste sentido, os padrões com maior probabilidade de serem mal classificados são rejeitados, ou não classificados, e manuseados com procedimentos mais sofisticados. Entretanto, altas taxas de rejeições geralmente consomem muito tempo em aplicações práticas. Desta forma um consenso entre erro e rejeição é necessário.

A regra de rejeição de Chow [FUMERA et al., 2000], desta forma, provê um ótimo ponto de erro-rejeição, somente se as probabilidades a posteriori das classes dos dados forem exatamente conhecidas. Infelizmente em aplicações práticas tais probabilidades são afetadas por estimativas de erros. Desta forma, Fumera [FUMERA et al., 2000] propõe o uso de múltiplos limiares de rejeição. A tarefa de classificação com N classes de dados é caracterizada pela probabilidade a posteriori estimada P(Wi | x),i 1,...,N. i = Um padrão x é rejeitado se:

Redes Neurais Artificiais
Um sistema neural artificial básico é composto de neurônios agrupados em camadas. Um neurônio artificial pode consistir de valores de entradas, pesos, um valor limiar, e uma saída [WILSON, 1999]. O modelo de neurônio artificial i, denominado perceptron, pode ser visualizado na Figura 2.3. O modelo consiste de um combinador linear seguido por uma unidade não-linear. O combinador consiste em uma série de sinapses ou conexões (parâmetros ajustáveis) conectadas aos respectivos terminais de entrada, cujas saídas ponderadas são combinadas em um somador. Nesse somador também é conectado, como entrada, um sinal externo de polarização também conhecido como bias b. O bias tem o efeito de aumentar ou diminuir a entrada líquida da função de ativação, dependendo dela ser positiva ou negativa, respectivamente. A saída do somador, denominada de neti, é a entrada da unidade não-linear ou função de ativação contínua e diferençável [HAYKIN, 2001].
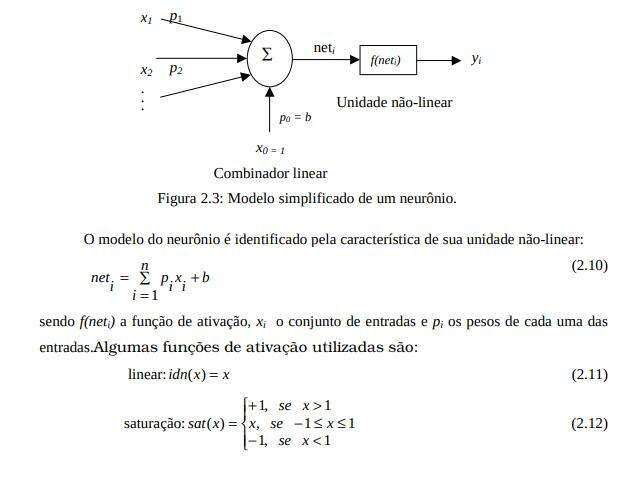
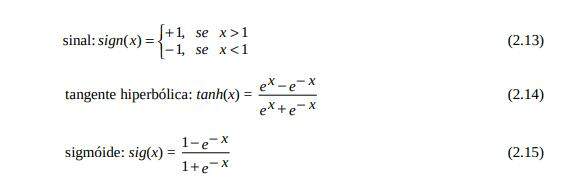
A função sigmoidal, que é a mais usada, possui esse nome devido ao formato em S (letra grega sigma) da função de ativação. Ela é uma função de fácil tratamento matemático, e usada em uma classe de redes neurais denominada MLP (Multilayer Perceptron), a qual utiliza o algoritmo de treinamento chamado algoritmo de Propagação Reversa (Backpropagation algortihm). A rede MLP corresponde a um modelo com unidades de processamento dispostas em camadas que se interconectam, uma após a outra, chegando até uma camada de saída. Com este algoritmo, o aprendizado ocorre de tal forma que os erros são inicialmente computados na camada de saída e então são consecutivamente computados nas camadas anteriores: daí o nome backpropagation [HAYKIN, 2001].
Perceptron Multicamadas
O Perceptron Multicamadas (MLP) é uma rede neural que consiste de uma camada de nós de entrada, uma ou mais camadas de nós-processadores ou computacionais (neurônios) ocultos ou escondidos e uma camada de saída também composta por nós computacionais. Os nós-fontes são utilizados para aplicação do sinal de entrada e os neurônios das camadas ocultas agem como detectores de características. Esses neurônios são ditos ocultos, pois eles são fisicamente inacessíveis pelas entradas ou pela saída da rede. Os neurônios de saída fornecem as respostas de rede neural aos sinais de entrada a ela apresentada [PRINCIPE et al., 2000]. O número de nós-fonte na camada de entrada é determinado pela dimensão do espaço de observação que é responsável pela geração dos sinais de entrada. O número de nóscomputacionais na camada de saída é determinado pela dimensão da resposta desejada. Assim, o projeto de uma MLP requer a preocupação em pelo menos três aspectos [WALCZAK & CERPA, 1999]:
• A determinação do número de camadas ocultas;
• A determinação do número de neurônios em cada uma das camadas ocultas;
• A especificação dos pesos ou ponderações em cada sinapse que conecta os neurônios.
O primeiro e o segundo itens estão relacionados com a complexidade da rede neural. A determinação dos pesos nas sinapses é tarefa para um algoritmo próprio, por exemplo, o algoritmo backpropagation. Essa determinação dos pesos pode ser vista como o armazenamento de informações do conteúdo dos dados utilizados no processo de treinamento, quando acontece o aprendizado, nos pesos das sinapses.
Melhorias de Desempenho da Rede Neural
Walczak e Cerpa [WALCZAK & CERPA, 1999] descrevem que o projeto de uma rede neural é uma problemática na qual existe um grande número de arquiteturas físicas alternativas de redes neurais e métodos de treinamento que podem ser aplicados para um dado problema de negócios. O objetivo é incorporar uma quantia significativa de conhecimento dentro do projeto de redes neurais mesmo antes do processo de aprendizagem ter começado. O desempenho da generalização de aprendizagem supervisionada de redes neurais backpropagation geralmente melhora quando o tamanho da rede é minimizado com respeito aos pesos das conexões entre nós de processamento (elementos de entrada, escondidos, e camadas de saída). As seguintes situações resultam em uma pobre generalização das amostras: redes que são grandes demais tendem para a memorização dos dados de entrada e redes com poucas conexões não contêm elementos de processamento suficiente para corretamente modelar o conjunto de dados de entrada.
De acordo com Lippmann [LIPPMANN, 1987], o número de nós deve ser grande o suficiente para formar uma região de decisão que seja tão complexa quanto requerido pelos dados do problema, porém não deve ser tão grande a ponto de muitos pesos não serem confiáveis. Dentro deste contexto, a seleção de variáveis de entrada é uma importante e complexa tarefa para o projeto de redes neurais. As redes neurais melhoram o desempenho com domínio adicional de conhecimento provido através de variáveis de entrada.
Se uma quantia suficiente de informação representando o critério de decisão crítica não é dada para uma rede neural, então a mesma não pode desenvolver um correto modelo do domínio. É comum acreditar que a aprendizagem em redes neurais é capaz de determinar variáveis de entrada que são importantes e desenvolver um correspondente modelo através da modificação de pesos associados às conexões entre as camadas de entrada e camadas escondidas. Walczak e Cerpa [WALCZAK & CERPA, 1999] estabelecem que o primeiro passo para determinar o conjunto ótimo de variáveis de entrada é voltado para o desempenho de aquisição de conhecimento padrão. O propósito primário da aquisição do conhecimento é para garantir que o conjunto das variáveis de entrada esteja suficientemente especificado, provendo o critério de todos os domínios relevantes para a rede. Se duas variáveis têm uma alta correlação, então uma destas duas variáveis pode ser removida do conjunto de variáveis sem afetar o desempenho da rede.
m Petersen [PETERSEN et al., 2002] é discutido o problema que envolve um grande número de dimensões de entrada na classificação em processamento de imagens, especialmente quando os algoritmos são aplicados diretamente nos pixels dos dados. O projeto de camadas escondidas depende da seleção do algoritmo de aprendizagem. Por exemplo, métodos de aprendizagem não supervisionada tais como ART normalmente requerem que a quantidade de nós da primeira camada escondida seja igual ao tamanho da camada de entrada. Já métodos supervisionados são geralmente mais flexíveis no projeto de camadas escondidas [WALCZAK & CERPA, 1999].
Embora seja possível projetar uma rede neural sem camadas escondidas, este tipo de rede pode somente classificar dados de entrada que são linearmente separáveis, os quais limitam severamente suas aplicações. Redes neurais artificiais que contêm camadas escondidas têm a habilidade para lidar de forma robusta com a não-linearidade e problemas complexos e, portanto, podem operar em problemas mais interessantes. É possível especificar, de forma geral, a quantidade de camadas escondidas correspondente à complexidade do domínio do problema a ser resolvido. Redes simples sem camadas escondidas criam um hiperplano. Já uma camada escondida combina hiperplanos de forma convexa nas áreas de decisão e duas camadas escondidas na rede combinam áreas de decisão de forma convexa que contêm regiões côncavas.
Uma interpretação geométrica adotada e modificada de Lippmann [LIPPMANN, 1987] na Figura 2.4 demonstra a capacidade do perceptron em separar regiões de decisão com uma, duas e três camadas em um espaço bidimensional. A segunda coluna desta figura indica o tipo de decisão que pode ser formada com diferentes redes. As próximas duas colunas apresentam regiões de decisão, as quais representam o problema do OU exclusivo e regiões misturadas. Um simples perceptron pode formar somente a metade das regiões de decisão, desta forma não é capaz de solucionar problemas que não sejam linearmente separáveis, conforme a primeira linha da Figura 2.4, já uma rede com uma camada escondida pode formar limites de decisão mais complexos como mostrado na segunda linha da Figura 2.4.
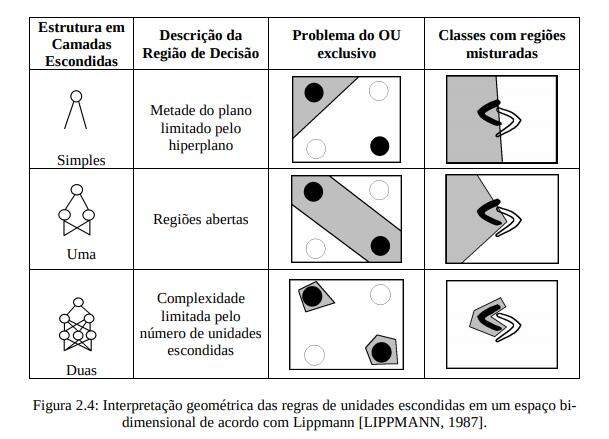
Na Figura 2.4 uma análise é feita com relação ao número de camadas e nós de acordo com Lippmann [LIPPMANN, 1987]. Em relação ao número de nós, dois nós são suficientes para resolver o OU exclusivo como na segunda linha da Figura 2.4. Mas na quarta coluna é demonstrado que nenhum número de nós com uma camada escondida pode separar as classes com regiões misturadas. Um perceptron com duas camadas escondidas forma arbitrariamente regiões de decisões complexas e separa as classes com regiões misturadas conforme a terceira linha da Figura 2.4. A análise acima demonstra que não mais que duas camadas escondidas são requeridas no perceptron como redes feedforward pelo fato de uma rede com duas camadas escondidas gerar arbitrariamente regiões de decisão complexas. Uma heurística para determinar a quantidade de camadas escondidas requerida por uma rede neural é proposta por Walczak e Cerpa [WALCZAK & CERPA, 1999], o qual acredita que com o aumento da dimensionalidade do espaço do domínio do problema, o número de camadas escondidas deveria aumentar correspondentemente.
O número de camadas escondidas é heuristicamente determinado pelo número de passos intermediários, dependente da categorização prévia, para transportar as variáveis de entrada em um valor de saída. Portanto, o domínio de um problema que tem uma solução de uma equação não-linear padrão é possivelmente resolvível por uma rede neural com uma simples camada escondida. Uma regra estabelecida com relação à quantidade de camadas escondidas é que uma grande quantidade delas habilita a rede neural a melhorar sua proximidade de ajuste, enquanto uma pequena quantidade melhora a suavidade ou a capacidade de extrapolação da rede. Para se escolher o número de nós a ser incluído em uma camada escondia, deve-se levar em conta o tempo e a precisão do treinamento. Um grande número de nós nas camadas escondidas resulta em um período mais longo de treinamento, enquanto que poucos nós provêm um treinamento mais rápido, pelo custo de se ter um detector de característica menor.
Muitos nós escondidos em uma rede habilita a mesma a memorizar o conjunto de dados de treinamento, produzindo um pobre desempenho de generalização. Walczak e Cerpa [WALCZAK & CERPA, 1999] descrevem algumas heurísticas existentes para selecionar a quantidade de nós escondidos para uma rede tal como: usar 75% da quantidade de nós de entrada, usar 50% da quantidade de entrada e saída, ou usar 2n + 1 nós na camada escondida em que n seria o número de nós na camada de entrada. Estas heurísticas de algoritmos não utilizam domínio do conhecimento para estimar a quantidade de nós escondidos e podem não ser as mais produtivas.
De acordo com Fujita [FUJITA, 1998], o número de unidades escondidas em uma rede neural feedfoward é significante na caracterização do desempenho da rede. Ela influencia a capacidade da rede, a habilidade da generalização, a velocidade de aprendizagem e, ainda, a resposta de saída. Normalmente ocorre que uma rede tem um desempenho pobre até um número suficiente de unidades escondidas que representam a correlação entre o vetor de entrada e os valores de saída desejada, e com o aumento do número de unidades escondidas além do suficiente, aumenta-se o tempo de treinamento sem um correspondente aumento na precisão da saída.
Aprendizagem em Redes MLP
Um processo de aprendizagem na rede neural pode ser visto como um problema de alterar a arquitetura da rede e as conexões de pesos, tal que a rede neural possa eficientemente aprender. Desta forma a rede geralmente adquire conhecimento baseado nas conexões de pesos dos padrões de treinamento disponíveis. A habilidade das redes neurais, para automaticamente aprenderem, baseadas em padrões, faz delas uma área excitante e atrativa. Ao invés de seguir um conjunto de regras especificado por peritos humanos, a rede neural trata a aprendizagem baseada em regras de relação de entrada-saída de uma dada coleção de exemplos representativos. Esta é uma das maiores vantagens da rede neural sobre sistemas de tradicionais.
Para entender ou projetar um processo de aprendizagem, deve-se primeiro ter um modelo de ambiente no qual uma rede neural opera, isto é, identificar qual informação está disponível para a rede, o que seria um paradigma de aprendizagem. Em segundo deve-se entender como os pesos da rede são atualizados, ou seja, qual regra de aprendizagem governa o processo de atualização. Um algoritmo de aprendizagem se refere a um procedimento no qual regras de aprendizagem são usadas para ajustar os pesos. Há três principais paradigmas de aprendizagem [RASHA, 1994]: supervisionado, não supervisionado e híbrido. No supervisionado a rede é provida com a resposta correta na saída para cada padrão de entrada. Pesos são determinados para permitir à rede produzir respostas tão próximas quanto possíveis para as respostas corretas conhecidas. Aprendizagem por reforço é uma variação de aprendizagem supervisionada na qual basicamente a rede é provida somente com uma crítica (de fortalecimento ou enfraquecimento) na saída da rede.
Em contrapartida, a aprendizagem não-supervisionada não requer uma resposta correta associada com cada padrão de entrada no conjunto de dados da aprendizagem. Ela explora a estrutura dos dados, ou correlação entre dados nos padrões, e organiza os padrões dentro de categorias desta correlação. Aprendizagem híbrida combina aprendizagem supervisionada e não-supervisionada. Parte dos pesos são geralmente determinados por aprendizagem supervisionada, enquanto outros são obtidos através de aprendizagem não-supervisionada.
A teoria da aprendizagem deve endereçar três visões fundamentais e práticas associadas com a aprendizagem das amostras: capacidade; complexidade das amostras, e complexidade computacional. A capacidade se preocupa em compreender como muitos padrões podem ser armazenados, e também que funções e limites de decisão uma rede pode formar. A complexidade das amostras determina o número de padrões de treinamento necessários para treinar a rede para garantir uma generalização válida A complexidade computacional refere-se ao tempo requerido para um algoritmo de aprendizagem estimar uma solução de padrões de treinamento.
Balanceamento de classes em redes MLP
Lawrence [LAWRENCE et al., 1998] tentam confrontar a idéia de que em métodos de classificação que utilizam redes MLP há problemas em relação às probabilidades a priori de classes individuais. Se o número de exemplos de treinamento que corresponde a cada classe variar significantemente entre as classes, a estimação precisa de uma probabilidade Bayesiana a posteriori requer que a rede seja: grande o suficiente, que o treinamento convirja para um mínimo global, possua dados de treinamento infinito, e que a probabilidade da classe a priori do conjunto de teste seja corretamente representada no conjunto de treinamento. Se o número de exemplos de treinamento para cada classe variar significantemente entre as classes, então há necessidade de um bias para predizer a classe mais comum, podendo conduzir a um pior desempenho de classificação para as classes mais raras.
Lawrence [LAWRENCE et al., 1998] citam que em alguns problemas de classes com baixa probabilidade a priori, nenhuma amostra foi classificada como estas classes depois do treinamento, concluindo que os problemas de balanceamento indicam que ou a estimação de probabilidade a posteriori Bayesiana é imprecisa, ou que tal estimação pode não ser a desejada. Um método simples para aliviar esta dificuldade de desigualdade das probabilidades a priori das classes de acordo com Lawrence [LAWRENCE et al., 1998] é ajustar o número de padrões em cada classe, ou por sub-amostragem, neste caso removendo padrões de classes de alta freqüência, ou por duplicação de padrões em classes de baixa freqüência. Por subamostragem, padrões podem ser removidos aleatoriamente, ou heuristicamente removendo padrões em regiões de baixa ambigüidade. A sub-amostragem envolve uma perda de informação que pode ser prejudicial. Já a duplicação envolve uma grande base de dados e um maior tempo de treinamento para o mesmo número de épocas de treinamento (tempo de convergência pode ser maior ou menor).
Chan e Stolfo [CHAN & STOLFO, 1998] demonstram que a distribuição das classes, no treinamento, afetam o desempenho dos classificadores e a distribuição natural pode ser diferente da distribuição desejada do treinamento as quais maximizam o desempenho. Japkowicz [JAPKOWICZ, 2000] tenta demonstrar que nem sempre os diferentes tipos de desbalanceamento de dados afetam o desempenho da classificação, assim como Weiss e Provost [WEISS & PROVOST, 2001] demonstram que conjuntos de dados balanceados nem sempre produzem os melhores resultados. Japkowicz demonstra que alguns métodos podem contornar problemas de balanceamento como:
• ‘upsizing’, método em que a classe representada por um pequeno conjunto de dados é aumentado, tal que se iguala ao tamanho da classe majoritária.
• ‘downsizing’, método, em que a classe representada por um grande conjunto de dados pode ser diminuída para igualar o tamanho da classe majoritária.
A conclusão de Japkowicz [JAPKOWICZ, 2000] é que o tamanho do conjunto de treinamento, com dados que são linearmente separáveis parecem ser insensitivos ao desbalanceamento, porém à medida que a complexidade aumenta o sistema torna-se sensitivo ao desbalanceamento de dados. Outra conclusão é que à medida que o tamanho do conjunto de treinamento aumenta, o grau de desbalanceamento tenderá a diminuir a taxa de erro. Isto sugere que em grandes domínios, o problema do balanceamento de classes pode não ser um impedimento para sistemas de classificação.
Especificamente, a visão da relativa cardinalidade de duas classes, que é freqüentemente um problema relacionado ao desbalanceamento de classes, pode de fato ser facilmente superado pelo uso de um grande conjunto de dados. Desta forma, o estudo de Japkowicz aponta que o desbalanceamento é um problema relativo dependente da complexidade do problema, representado pelos dados no qual o balanceamento ocorre, como também pelo tamanho global do conjunto de treinamento, em adição ao grau de balanceamento das classes presente nos dados.
Rasha [RASHA, 1994] e Lee [LEE, 1995] utilizam conjuntos com diferentes cardinalidades de amostras para cada classe durante a fase de treinamento em abordagens de verificação de assinaturas utilizando redes neurais. Lee [LEE, 1995] em experimentos com conjuntos de cardinalidades diferentes revela o desempenho superior com a incorporação de falsificações aleatórias na fase de aprendizagem, porém com amostras desbalanceadas.
Considerações sobre o treinamento em redes MLP
De acordo com Rasha [RASHA, 1994] muitos esforços são requeridos para projetar uma rede neural MLP. Durante o treinamento, pode-se notar que a estratégia de ajustar os pesos torna-se um processo muito lento, podendo permanecer em um mínimo local, ou tornando-se instável e oscilando entre soluções. A seguir são apresentados alguns parâmetros de treinamento a serem considerados:
• Treinamento por padrão ou por época: Quando se treina a rede, o erro é calculado e cada unidade na rede tem seus pesos ajustados tal que ele reduz o valor da função de erro. Os pesos da rede podem ser ajustados para cada padrão de treinamento e conseqüentemente implementa-se o treinamento por padrão. Uma alternativa é treinar por época. Uma época é uma varredura de todos os padrões no conjunto de treinamento. Conseqüentemente, uma correção acumulada do conjunto de pesos é executada depois de cada época de treinamento. Métodos de treinamento intermediário ou híbrido também são possíveis;
• Baixando a constante de aprendizagem 2: 2 é a aprendizagem (ou termo de ganho) que especifica a largura do passo de treinamento. Se o termo de ganho começar com valores grandes, grandes serão os passos em relação aos pesos e superfície de erro para a solução. Se a superfície mudar rapidamente, um grande ganho pode causar uma oscilação no sistema, que poderá demorar ou impedir a convergência. Em contrapartida, se a superfície é relativamente suave, então haverá um grande ganho de velocidade de convergência;
• Vetores de treinamento em ordem sequencial ou aleatória: este parâmetro é importante para otimizar a aprendizagem para que vários padrões sejam apresentados em diferentes ordens em diferentes ciclos. Pensando em alguns problemas, é valido destacar que uma ordem sequencial de vetores de treinamento pode ser requerida para enfatizar certas propriedades, mas uma ordem aleatória de vetores de treinamentos é geralmente indicada.
• Supertreinamento (Overtraining): uma importante questão a ser considerada é quando parar o treinamento. Se a rede é treinada demasiadamente, o erro é minimizado por organizar os discriminantes muito especificamente, para o conjunto de treinamento. Desde que um conjunto de treinamento contenha apenas uma fração de exemplos possíveis de uma classe, estes discriminantes seriam firmemente focados em características particulares do conjunto de treinamento. Quando tal rede for usada para classificar amostras que não foram utilizadas no treinamento, estes discriminantes altamente específicos tem uma pobre generalização e executam com menos precisão que uma rede que não foi supertreinada. Uma maneira para superar este problema é quebrar o treinamento em dois conjuntos. A primeira parte é usada para treinar de modo habitual. A segunda parte é usada a cada n ciclos para controlar a curva de aprendizagem. Quando o erro começar a subir neste segundo conjunto o treinamento é interrompido, e a rede é testada pelo conjunto de teste. Outra maneira de parar o treinamento é escolher um valor de erro e esperar que o valor seja atingido, o que pode causar uma sub-ajuste (underfitting) ou um sobre-ajuste (overfitting).
De acordo com Moody [MOODY, 1994] é mais fácil ocorrer um sobre-ajuste no treinamento com um conjunto pequeno de treinamento. Desta forma, deve-se tomar cuidado para não selecionar um modelo que seja grande demais, pois o mesmo resulta em um longo tempo de convergência e o desempenho global conseqüentemente nunca é perfeito. Também conjuntos de dados limitados fazem a estimação do risco de predição mais difícil, se não houver dados suficientes disponíveis. Nestas situações, é preciso usar abordagens alternativas que habilitem a estimação do risco de predição dos dados separadamente como a re-amostragem, usando, por exemplo, validação cruzada tipo kpartições [PLUTOWSKI, 1996].
De acordo com Moody [MOODY, 1994] é mais fácil ocorrer um sobre-ajuste no treinamento com um conjunto pequeno de treinamento. Desta forma, deve-se tomar cuidado para não selecionar um modelo que seja grande demais, pois o mesmo resulta em um longo tempo de convergência e o desempenho global conseqüentemente nunca é perfeito. Também conjuntos de dados limitados fazem a estimação do risco de predição mais difícil, se não houver dados suficientes disponíveis. Nestas situações, é preciso usar abordagens alternativas que habilitem a estimação do risco de predição dos dados separadamente como a re-amostragem, usando, por exemplo, validação cruzada tipo kpartições [PLUTOWSKI, 1996].
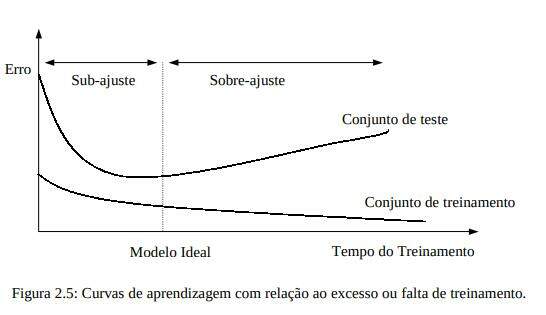
O erro esperado do treinamento e teste com relação à bias / variança para amostras finitas de treinamento é ilustrada na Figura 2.5. De acordo com Zhang [ZHANG, 2000] bias e variança são, na maioria das vezes, incompatíveis. Com um conjunto de dados fixado, o esforço em reduzir um implicará no aumento do outro.
Um bom compromisso entre bias e variança é necessário para construir um classificador baseado em redes neurais. Na Figura 2.5 notam-se regiões de sub-ajuste (bias elevado) e de sobre-ajuste (variância), em que técnicas de seleção do modelo ideal tentam encontrar o ponto ótimo entre falta e excesso de treinamento, os quais correspondem a um mínimo global dos erros do conjunto de teste ou curva de risco de predição.
Estimando o desempenho de redes MLP
O objetivo de qualquer problema de classificação é classificar e predizer com sucesso um novo dado. Entretanto, na maioria das formulações práticas uma regra de classificação pode não lidar perfeitamente com este problema. Há sempre a probabilidade de um erro de classificação. Um erro é uma má classificação: ao classificador é apresentado um caso e ele classifica-o incorretamente. Uma razão para isto é o fato de existirem características comuns para duas ou mais classes. Por exemplo, uma curva de distribuição normal de duas classes, disposta conforme Figura 2.6 de acordo com Rasha [RASHA, 1994].
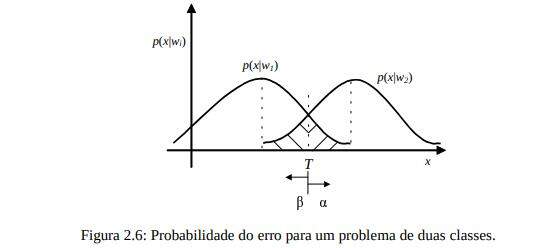
As probabilidades do erro de classificação conforme a Figura 2.6 podem, por exemplo, ser calculadas como:
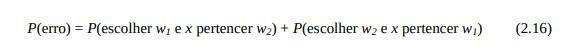
Em geral nos problemas de classificação de padrões pode haver dois tipos de erros de classificação:

Um limiar de decisão necessita ser estabelecido em qualquer problema de classificação. Na Figura 2.6 T representa este limiar. A escolha segue os critérios para minimizar a média do erro de falsa rejeição e falsa aceitação tentando minimizar o custo do erro. Para avaliar as medidas de desempenho que levem em conta a probabilidade de um erro de classificação, a significância e o custo de um erro, algumas medidas de desempenho são necessárias como:
• Taxa de erro aparente: é a taxa de erro atual que o classificador aparentará, quando aplicado para todos os casos desconhecidos que ele tratar. Se um número ilimitado de classes estiver disponível, a taxa de erro verdadeira será computada como o número de amostras infinitamente abordadas. Entretanto, em casos práticos, o número de amostras disponíveis é finito, e relativamente pequeno. A taxa de erro aparente ou empírica é calculada, como notada na equação (2.17), como sendo o número de erros feitos pelo classificador em relação ao número de amostras.

Conseqüentemente quanto maior o de número de amostras, a taxa aparente estará mais próxima da taxa de erro verdadeira.
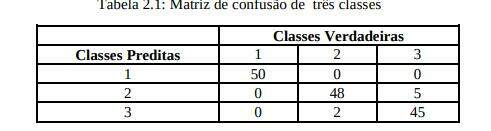
• Matriz de confusão: é uma matriz bi-dimensional usada para dispor os diferentes erros. A Tabela 2.1 ilustra uma matriz de confusão para três classes. A matriz de confusão lista a correta classificação contra a classificação predita para cada classe. Enquanto os elementos diagonais na matriz de confusão representam o número de classificações corretas, os elementos fora da diagonal representam o número de erros para um particular tipo de erro de má classificação. Portanto uma matriz de confusão desejada ter um valor máximo nos elementos diagonais e valor zero fora dela.
Métodos de Validação do Processo de Aprendizagem
A essência do aprendizado backpropagation é codificar uma relação funcional entre entradas e saídas representada por um conjunto de exemplos rotulados. A esperança é que a rede torne-se bem treinada, de modo que ela aprenda bastante sobre o passado, para poder generalizar sobre o futuro. Sob esta perspectiva, o processo de aprendizado equivale a uma escolha de parametrização da rede para este conjunto de exemplos. Mais especificamente, pode-se ver o problema de seleção da rede como sendo um problema de escolha, dentro de um conjunto de estruturas de modelo candidatas (parametrizações), de acordo com um certo critério. Dentro deste modelo, o método holdout fornece um procedimento atrativo. Primeiro o conjunto de dados disponível é particionado aleatoriamente em um conjunto de treinamento e em um conjunto de teste. O conjunto de treinamento é depois particionado em dois conjuntos disjuntos: subconjunto de estimação, usado para selecionar o modelo; subconjunto de validação, usado para testar ou validar o modelo. Comumente utiliza-se um conjunto de validação para ajuste de parâmetros, como critério de parada também.
De acordo com Haykin [HAYKIN, 2001], o método de validação com divisão em duas partes (holdout validation) é um dos métodos mais comuns para estimar a generalização do erro. Este método, também chamado de teste de estimativa simples, particiona o conjunto de dados em dois subconjuntos mutuamente excludentes, chamados de conjunto de treinamento e conjunto de teste. É comum designar 2/3 do conjunto de dados para o conjunto de treinamento e 1/3 para o conjunto de teste. Provavelmente, a aplicação mais popular do método holdout é conhecida como parada com validação [PLUTOWSKI, 1996], do ponto de máxima generalização, e é aplicável para todo o procedimento de treinamento interativo, pois a otimização da aprendizagem ocorre em pequenos passos com uma interatividade ocasionando a solução sobre os conjuntos de treinamento e validação.
A forma básica consiste em medir o erro sobre um conjunto de validação após cada peso atualizado, continuando este processo enquanto o erro estiver decrementando, e parar quando o erro no conjunto de validação subir, ou se tornar estável o suficiente. Portanto, este método otimiza parcialmente o critério de aprendizagem no conjunto de treinamento, e na verdade, também otimiza o critério de aprendizagem no conjunto de validação. Desta forma o conjunto de treinamento é usado para prover informação independente da regra de atualização dos pesos. A parada com validação pode ser vista como o modo regular a generalização de um modelo durante o treinamento.
No método holdout como parada com validação nota-se que o conjunto de validação afeta o processo de aprendizagem. Portanto um terceiro conjunto de amostras independentes torna-se necessário (conjunto de teste) para obter uma estimativa precisa de desempenho de generalização do modelo treinado. Indiretamente com este método ocorre o processo de aprendizagem do conjunto de validação. Desta forma, para que se garanta que os dados de teste não sejam usados, o método de classificação opera com três conjuntos: conjunto de treinamento usado para construir a estrutura, conjunto de validação usado para otimizar ou ajustar parâmetros e também no critério de parada e o conjunto de teste usado para avaliar o desempenho.
SVM
Um problema encontrado em redes neurais artificiais, em específico em redes MLP é inferir uma relação entre número de camadas escondidas e as classes, o qual é determinado heuristicamente. Uma alternativa para este problema pode ser o SVM (support vector machine), pois representa o papel de classificador em problemas de reconhecimento de padrões e tem sido utilizado recentemente em vários trabalhos relacionados a manuscritos como em Justino [JUSTINO et al., 2003] e Kholmatov, [KHOLMATOV, 2003] demonstrando alta performance com relação a ferramentas tradicionais de aprendizagem.
No SVM, os padrões de entrada são transformados para um vetor de características de alta dimensionalidade, cujo objetivo é separar no espaço as características linearmente. Neste caso o problema da aprendizagem é reduzido para o treinamento de um simples perceptron. Uma vez que o espaço adequado de características é definido, o SVM seleciona o hiperplano particular chamado hiperplano de margem máxima (MMH), o qual corresponde a maior distância de seus padrões no conjunto de treinamento. Estes padrões são chamados de vetores de suporte (SV). A idéia principal é separar as classes com superfícies que maximizem a margem entre eles. A Figura 2.7 demonstra um conjunto de dados de duas classes w1 e w2 linearmente separáveis com margem de separação máxima p ou hiperplano de separação ótima [OSUNA et al., 1997].
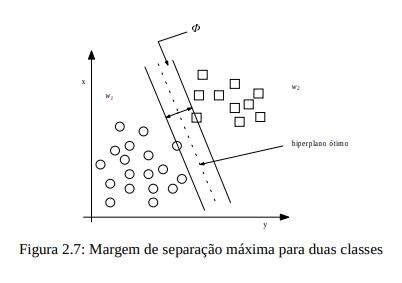
Para achar a superfície de decisão ótima, o algoritmo de treinamento dos vetores de suporte tenta separar da melhor forma possível os pontos de dados de ambas as classes, sendo que os pontos mais perto do limite entre as duas classes são selecionados, por serem mais importantes na solução do que os pontos que estão mais longes, os quais ajudam a definir a forma da melhor superfície de decisão que outros pontos. Problemas complexos exigem funções mais complexas de classificadores para a sua solução como um classificador polinomial, que forma superfícies de decisão diferenciadas conforme a Figura 2.8. Os vetores de suporte são representados por pontos com preenchimentos escuros.

De acordo com Mukkamalla [MUKKAMALLA et al., 2002], o SVM é baseado na idéia de minimização do risco estrutural, o qual minimiza o erro de generalização, isto é, erros verdadeiros em amostras não-vistas. O número de parâmetros livres usado no SVM depende da margem que separa os pontos de dados, mas não do número de características de entrada afim de evitar o sobre-ajuste. O SVM provê um mecanismo genérico de preencher a superfície de hiperplano por dados através de uso de uma função de kernel. O usuário pode prover uma função, tal como linear, polinomial, ou RBF, para o SVM durante o processo de treinamento, o qual seleciona vetores de suporte ao longo da superfície desta função. Esta capacidade permite classificar uma faixa de problemas maiores. O limite de decisão entre duas classes é definido pelo SVM:
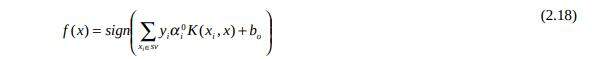


A ideia básica do SVM é mapear um espaço de entrada em um espaço de características de alta dimensionalidade. Este mapeamento pode ser feito linearmente ou não, de acordo com a função do kernel usada para o mapeamento. Neste novo espaço de características, o SVM constrói hiperplanos ótimos através dos quais as classes são separadas com objetivo de estabelecer uma margem maior entre cada classe e um erro mínimo na classificação. O hiperplano ótimo pode ser escrito como uma combinação de poucos pontos de características cujos pontos são chamados vetores de suportes do hiperplano ótimo [KHOLMATOV, 2003]. O SVM é baseado no princípio de minimização do risco estrutural (SRM). O princípio de indução (SRM) tem dois objetivos principais. Primeiro, controlar o risco empírico no conjunto de dados de treinamento e segundo controlar a capacidade da função de decisão usada para obter o valor deste risco. A função de decisão do SVM treinada linearmente f (x) é descrita pelo vetor de pesos p , um limiar b e padrões de entrada x :


Comentários Finais
A teoria descrita neste capítulo é de fundamental importância para a elaboração do presente trabalho. Os tipos de abordagens e métodos relacionados a verificação de assinaturas fornecem uma visão clara do presente trabalho situando o mesmo no contexto de reconhecimento de padrões. A introdução a redes neurais e principalmente as dicas de melhorias de desempenho das redes MLP relacionado a arquitetura da rede neural, são de grande valia para o presente trabalho, assim como representa uma contribuição para trabalhos futuros. A introdução ao SVM fornece subsídios para os experimentos realizados. No capítulo seguinte são descritas algumas abordagens relacionadas a verificação de assinaturas, classificadas por tipos de abordagens.
3 Estado da Arte na Autenticação de Assinaturas
Existe um número considerável de trabalhos [JUSTINO, 2001], [SABOURIN & GENEST, 1994], [XIAO & LEEDHAM, 1999] e [BALTZAKIS & PAPAMARKOS, 2001] sobre o problema de verificação de assinaturas. Por ser uma área que atrai muitos pesquisadores e sendo um problema ainda em aberto, a verificação automática de assinaturas, tanto on-line quanto off-line, possui trabalhos com abordagens distintas no que se refere a características, classificador e métodos usados. Neste capítulo alguns trabalhos que se relacionam com o tema são descritos separadamente por tipos de abordagens, assim como uma visão crítica do estado da arte.
Abordagens Globais
Deng [DENG et al., 1999] apresentam um sistema de verificação de assinaturas offline baseado em funções wavelet, utilizando um algoritmo de perseguição de contorno fechado para transformar as imagens de assinaturas em sinais unidimensionais. Os dados de curvatura de contorno são decompostos em sinais multiresolução usando transformada wavelet. Além disso, uma medida estatística é criada para decidir, sistematicamente, quais são os contornos fechados e os dados de frequências associados a estes contornos, demonstrando quais autores são mais estáveis e discriminantes relacionados a este critério. Baseando-se nestes dados, é calculado um valor de limiar ótimo que controla a precisão do processo de extração de características. O sistema utiliza imagens binárias na extração das características, usadas tanto em sistemas on-line quanto em off-line. A base de dados usada por Deng [DENG et al., 1999] é composta de 50 autores cada um com 20 assinaturas genuínas e 5 pessoas fornecem 10 tipos de falsificações dos 50 autores perfazendo um total de 3500 assinaturas.
Um outro método proposto por Bajaj e Chaudhury [BAJAJ & CHAUDHURY, 1996] utiliza três características globais. O uso de características globais dá-se pelo fato de que as mesmas trabalhavam com a forma da imagem, provendo um mecanismo mais rápido de acesso para os dados de assinatura, ao contrário de características locais que requerem técnicas computacionalmente onerosas para a determinação de similaridade. Bajaj e Chaudhury [BAJAJ & CHAUDHURY, 1996] usam momentos de projeção também usados por Marar [MARAR et al., 2002] e Ribeiro e Vasconcelos [RIBEIRO & VASCONCELOS, 1999], a qual utiliza uma medida estatística da distribuição dos pixels da assinatura e, ao contrário de outras características globais, é relativamente insensível a distorções e variações de estilo. Um outro tipo de característica, utilizado por Bajaj e Chaudhury [BAJAJ & CHAUDHURY, 1996] está relacionado com a distribuição extrema de pixels envolvendo os limites inferiores e superiores da assinatura, denominado envelopes. Para aumentar a confiabilidade da classificação, os resultados obtidos das três características são combinados em múltiplos classificadores.
A verificação é feita com base no vetor destas 3 características utilizando três redes MLP. O uso de múltiplos classificadores introduz um elemento de redundância no esquema, pois os erros de classificação são compensados por um simples classificador, se, é claro, outros classificadores não proverem a correta decisão. As saídas dos três classificadores são combinadas para a decisão final, através da estratégia do vencedor leva tudo. O método tem a vantagem de combinar evidências providas por diferentes tipos de características, porque no caso da haver confusão na classificação quanto à característica outro conjunto pode auxiliar. A base de dados usada no experimento é composta por 10 autores, cada um provendo 15 assinaturas e somente 100 assinaturas aleatórias dos 10 autores.
Nota-se, também, que o modelo de redes neurais mais amplamente utilizado em problemas relacionados à verificação de assinaturas é a rede MLP e o algoritmo backpropagation, porém Ribeiro e Vasconcelos [RIBEIRO & VASCONCELOS, 1999] utilizam arquiteturas construtivas (as quais constroem sua própria estrutura incluindo unidades e camadas intermediárias) Cascade-Correlation, Tower e Pyramid sob a abordagem auto associativa (em que as saídas são forçadas a reproduzir as entradas) sendo os resultados comparados com a rede MLP. Ribeiro e Vasconcelos acreditam que modelos de redes feedforward que atuam como classificadores não são adequados, pois a discriminação de classes neste tipo de rede é realizada por superfície de separação, a qual é gerada para particionar os dados de entrada.
No entanto, tais superfícies são abertas. Já as redes feedforward que atuam como auto associadores geram superfícies de separação fechadas, e tilizam critérios de rejeição relacionados à maneira com que a entrada se aproxima da saída. Na extração de características Ribeiro e Vasconcelos [RIBEIRO & VASCONCELOS, 1999] utilizam momentos invariantes, inclinação e fator de pressão global da imagem. Ao final o resultado em uma base de dados reduzida com 21 autores demonstra algum ganho com relação à falsa rejeição, mas nenhum acréscimo à falsa aceitação.
4 Abordagens Locais
O número de assinaturas genuínas do mesmo autor no processo de treinamento tornase um problema na maioria dos métodos propostos. Uma abordagem que procura minimizar este problema é proposta por Xiao e Leedham [XIAO & LEEDHAM, 1999], nesta abordagem uma rede neural MLP é usada como classificador. A base fundamental do método reside no fato que peritos forenses localizam primeiro as diferenças entre a assinatura de entrada e a assinatura genuína armazenada, comparando características locais, então analisam a variação destas características julgando se as mesmas são essenciais ou acidentais. Neste estudo, Xiao e Leedham [XIAO & LEEDHAM, 1999] tratam das partes estáveis da assinatura, ou seja, segmentos com menores variações, como também dos nós de resposta do classificador. Para alcançar estes objetivos, é usado um método para gerar falsificações artificiais das assinaturas genuínas assim como uma rede neural com realimentação apropriada dos pesos dos nós de resposta. Com relação às características, a distribuição dos pixels em quatro direções é utilizada dentro de um grid. Os resultados obtidos com poucos autores são aceitáveis, principalmente pelo número de assinaturas genuínas utilizadas (em torno de 9), porém é conveniente ressaltar que 9 autores voluntários são insuficientes para uma perfeita validação estatística.
Alguns trabalhos abordam o problema de falsificações aleatórias [MURSHED et al., 1995], em que o sistema é treinado somente com assinaturas genuínas. A alegação é que na prática nem sempre é possível obter assinaturas falsificadas, tornando-se impraticável quando aplicada em sistemas reais como aplicações bancárias. Para lidar com estas dificuldades alguns pesquisadores têm usado assinaturas de outros autores no sistema como sendo assinaturas falsas, as chamadas falsificações aleatórias. Neste caso, a taxa de falsa aceitação é artificialmente reduzida no contexto de falsificação, de acordo com Murshed. Por exemplo, se um sistema é treinado com assinaturas genuínas do escritor ‘a’ e com falsificações aleatórias dos escritores ‘b’, ’c’ e ‘d’, então o sistema adquire um conhecimento de características contidas nas assinaturas destes escritores.
Durante a fase de avaliação quando o sistema é confrontado com assinaturas dos escritores ‘b’, ’c’ e ‘d’ como sendo falsificações aleatórias, ele usa seu conhecimento adquirido durante o treinamento, e provavelmente classifica estas assinaturas como aleatórias. Ainda no trabalho de Murshed, nota-se que o desempenho final pode não ser o mesmo se introduzidas assinaturas de autores que não contribuem para a fase de treinamento. Durante o estágio de treinamento, o sistema aprende características das assinaturas genuínas de um dado escritor, formando tantas classes de categorias quantas são as características distintas. Quando o treinamento termina, o sistema tem conhecimento somente de assinaturas genuínas deste escritor. Semelhante a abordagem de Sansone e Vento [SANSONE & VENTO, 2000], no método de Murshed [MURSHED et al., 1995] o primeiro estágio centraliza a imagem e dividi a mesma em regiões (grid). Em seguida segmentos gráficos de tamanho fixos são extraídos de cada região e modelada por uma rede neural para reduzir o tamanho destes segmentos. No estágio seguinte cada uma das regiões é modelada por uma rede Fuzzy ARTMAP.
Finalmente, o estágio de decisão analisa os resultados produzidos para cada Fuzzy ARTMAP e toma a decisão sobre a autenticidade das assinaturas. Para dividir a assinatura de entrada durante o treinamento/verificação em regiões, uma identidade de grid é projetada para cada escritor, tal que sua forma reflete a média global das assinaturas de referências deste referido escritor. Neste método usa-se memória associativa através de uma rede backpropagation para a redução da dimensionalidade aplicada nas imagens e a saída do primeiro estágio forma um vetor com 768 entradas nas redes Fuzzy ARTMAP. A base de dados usada é composta por 200 assinaturas de 5 autores, com 40 assinaturas genuínas. Nesta abordagem, como na maioria dos trabalhos correlatos, demonstra-se que os melhores desempenhos são obtidos com um número maior de assinaturas genuínas por autor no treinamento.
Também Zhang [ZHANG et al., 1998] propõem um método de verificação de assinaturas baseado na técnica de quantização vetorial, em que um número de codebooks é estabelecido para palavras de cada pessoa e a classificação é estabelecida num esquema de reconstrução chamada decodificador da população. Para este método usam-se 3770 assinaturas de 19 autores. As imagens são normalizadas em tamanho fixo de 240 por 120 pixels. Na extração de características duas técnicas são usadas. Na primeira, a imagem é segmentada em regiões de 24 x 12 e para cada região são contados os pixels. Na outra técnica, usa-se a transformação de escala de cinza por região, sendo aplicada uma máscara de tamanho 3 x 3 sobre as regiões de tamanho 80 x 40. Zhang [ZHANG et al., 1998] enfatizam a necessidade de se coletar as assinaturas em tempos distintos, para tanto realizam experimentos diferenciados com amostras coletadas em períodos distintos.
Outra abordagem que utiliza a geração de assinaturas genuínas artificiais para treinamento é proposta por Huang e Yan [HUANG & YAN, 1997] com uma variante em que assinaturas artificiais com alto grau de distorção são incorporadas como falsificação no processo de treinamento. Um modelo de segmentação em células de tamanhos diferenciados é aplicado na extração das características locais. As características geométricas são obtidas do núcleo da assinatura, do contorno, da distribuição dos pixels, de fronteiras direcionais e da região de máxima pressão. A base de dados usada é de 3528 assinaturas de 21 autores sendo que cada autor cede 24 assinaturas genuínas e 6 outras pessoas produzem 24 falsificações dos 21 autores. Vários níveis de resolução do grid são testados, sendo um nível para cada rede, a qual compôs as características dentro do tamanho do grid em específico. Após o treinamento individual de cada rede, as saídas são passadas para uma outra rede neural cuja função é combinar as respostas de cada rede e produzir uma decisão.
Sabourin e Genest [SABOURIN & GENEST, 1994] propõem uma abordagem local com características estatísticas. Este método utiliza a técnica denominada Extended-ShadowCode na qual as operações de projeções são definidas em um grid, ocorrendo simultâneas projeções para cada pixel preto nas barras horizontais, verticais e na diagonal. A projeção contém um conjunto de bits distribuídos ao longo de cada barra, os quais são contados. O método de verificação é estatístico e utiliza dois classificadores knn (vizinho mais próximo) e um classificador de mínimas distâncias. Com relação ao uso de uma base de dados Sabourin e Genest [SABOURIN & GENEST, 1994] utilizam 800 assinaturas, sendo 40 assinaturas produzidas por 20 autores distintos.
De acordo com Justino [JUSTINO et al., 2002] cada tipo de falsificação requisita um método de reconhecimento diferente. Métodos baseados em abordagens estáticas são usados para identificar falsificações aleatórias e simples. A razão é que estes métodos descrevem melhor as características relacionadas à forma da assinatura. A abordagem baseada na grafometria [JUSTINO et al., 2002] supre esta lacuna do uso de métodos de reconhecimentos diferentes, em relação à escolha do tipo de características, pois engloba características que possuem um tratamento local, as chamadas pseudodinâmicas. Justino utiliza a característica pseudodinâmica inclinação axial que descreve adequadamente o movimento da escrita, como ambém utiliza características estáticas representadas pela densidade de pixels e a sua distribuição.
Justino [JUSTINO et al., 2002] usam a imagem binária dentro de um grid para extrair as características. Na densidade de pixels, a contagem é efetuada em cada região do grid (célula), já a distribuição representa a distribuição geométrica dentro da célula. Na inclinação axial, os pixels pretos são projetados nos 4 sensores da periferia de cada célula, usando como base o eixo central da célula. Cada sensor prove um valor numérico que corresponde ao total de pixels projetados. Este valor numérico é normalizado pelo tamanho do sensor. Um conjunto de codebooks gerado para cada característica utiliza uma base de dados específica para a geração do léxico. No processo de quantização vetorial o algoritmo k-means é utilizado. Este procedimento tem como objetivo a redução da dimensionalidade dos vetores gerados, que são então enviados ao classificador HMM para o processo de aprendizagem. Como o treinamento é baseado em um modelo pessoal, Justino [JUSTINO et al., 2002] determina limiares de aceitação e rejeição levando em conta cada autor em específico, desta forma melhora os resultados. A base de dados deste experimento é composta por 5200 assinaturas de 100 autores sendo 4000 genuínas correspondendo a 40 assinaturas de 100 autores e 1200 falsificações simples e simuladas.
5 Abordagens Globais e Locais
Sistemas em que a aplicação enquadra-se em qualquer contexto despertam interesse de pesquisadores. Qi e Hunt [QI & HUNT, 1994], propõem a representação de características invariantes à mudança de escala nas assinaturas, sendo usadas características globais e geométricas como altura, largura, centro de gravidade, ângulo de inclinação e projeções, e ainda características locais representadas por um grid. No processo de verificação utiliza-se um sistema multi-escala baseado em distância euclidiana. Nesta abordagem 25 autores são usados, com 15 autores que provem 20 assinaturas genuínas e os 10 restantes cedem 15 falsificações perfazendo um total de 450 assinaturas para o treinamento e teste. Para esta verificação, utilizam-se somente medidas de distâncias.
Sansone e Vento [SANSONE & VENTO, 2000] propõem um sistema baseado em rede neurais com múltiplos estágios de decisão no processo de verificação. Cada estágio é representado por uma rede MLP usando um conjunto adequado de características. O primeiro estágio adota somente características globais (a estrutura da assinatura) e é dedicado à eliminação de falsificações simples e aleatórias, mas, mesmo com a generalidade empregada, implica em um efeito não desejado, no qual algumas falsificações simuladas são aceitas como genuínas.
O segundo estágio recebe apenas assinaturas não classificadas como falsas no primeiro estágio (isto é, aquelas assinaturas realmente genuínas, ou falsificações reproduzidas de uma maneira simulada que enganaram o primeiro estágio), e adota uma característica específica para esta tarefa, neste caso, são usadas regiões de alta pressão. Ambos os estágios empregam um critério para estimar a confiabilidade do desempenho do classificador, tal que, quando há incerteza quanto à assinatura, esta é remetida para um estágio que toma a decisão final, levando em conta a decisão dos estágios prévios junto com a correspondente estimação de confiabilidade. Na avaliação da confiabilidade, o sistema usa limiares de rejeição. A base de dados do experimento é composta de 49 autores sendo 20 assinaturas genuínas por autor e um total de 1960 assinaturas.
Faez [FAEZ et al., 1997] propõem um método de verificação de assinaturas utilizando redes neurais baseado em características de descritores de forma: esqueleto da imagem, baixo envelope e alto envelope, e regiões de alta pressão, sendo esta última característica extraída em níveis de cinza. Sobre cada imagem de assinatura alinhada é sobreposto um grid de 5x10 extraindo características locais da imagem. Uma rede MLP para cada descritor de forma, ou seja, cada característica é treinada, e no final cada nó de saída da rede fornece uma medida de confiança na decisão. Para encontrar a decisão ótima usa-se a decisão integral Fuzzy combinando as saídas individuais de cada rede. Faez [FAEZ et al., 1997] geram assinaturas genuínas artificiais, uma vez que a abordagem propõem o uso de quantidade reduzida de amostras por autor. A base de dados possui 50 autores: cada autor com 10 assinaturas genuínas e outras pessoas fornecendo 10 falsificações por autor, sendo 5 simuladas e 5 simples. No total 1000 assinaturas mais 40 assinaturas por autor geradas artificialmente são utilizadas
Baltzakis e Papamarkos [BALTZAKIS & PAPAMARKOS, 2000] propõem um novo método com habilidade de verificar e reconhecer a assinatura em um processo multi-estágio utilizando classificadores neurais. O sistema é baseado no uso de três grupos de características: as globais, nas quais se encaixam a altura da assinatura, área da imagem, largura da imagem, comportamento base, projeções vertical e horizontal, curvatura, pontos de borda, cruzamentos e laços. Outro grupo extrai informações locais do grid, no qual os pixels pretos são contados e normalizados em 0 ou 1 de acordo com a quantidade de pixels dentro de cada região.
Uma outro grupo de característica utilizada é a textura com uso da matriz de coocorrência da imagem em nível de cinza dividindo em regiões para sua extração. No primeiro estágio, cada grupo de característica é dado entrado em uma rede MLP separadamente e a distância euclidiana também é extraída das características. O segundo estágio, composto das saídas das características do primeiro estágio e da distância euclidiana das características, representa quatro entradas em uma rede RBF baseada na qual a decisão final é tomada. A base de dados é composta de 2000 assinaturas de 115 autores. Cada autor prove 15 ou 25 assinaturas.
A Tabela 3.1 abaixo demonstra o resumo das abordagens apresentadas com seus respectivos diferenciais em termos de tipos de abordagens e características, que fazem parte do ponto de partida para este trabalho.
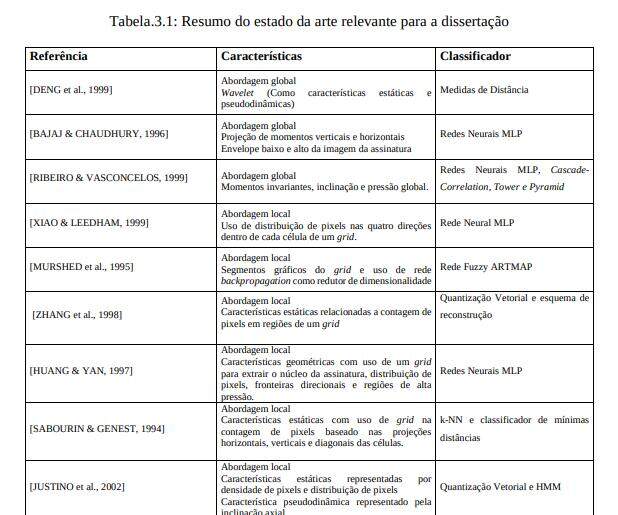
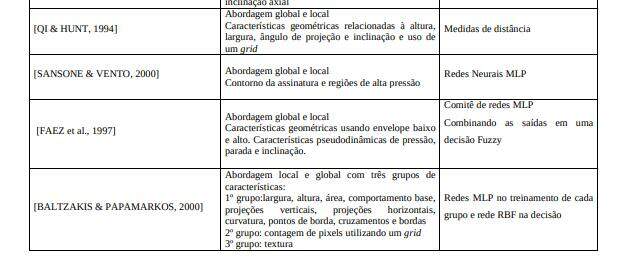
6 Visão Crítica do Estado da Arte
A visão crítica proposta busca contribuir para uma abordagem mais consistente e que possua conotação prática. Entretanto, uma comparação mais refinada em termos de resultados estatísticos em cada abordagem torna-se difícil, justamente pela diversidade de bases de dados e protocolos experimentais existentes, e também por não existir nenhuma base de dados internacional compartilhada, implicando um grande problema para a comparação de desempenho entre métodos [FANG et al., 2003] [MURSHED et al., 1995]. Os resultados apresentados por algumas abordagens mostram taxas de erros baixas, porém quando analisados profundamente demonstram que tratam apenas de alguns tipos de falsificações, desconsiderando, por exemplo, as falsificações simuladas [BALTZAKIS & PAPAMARKOS, 2000].
É comum ter soluções combinando diferentes tipos de classificadores, pois cada um contribui de maneira diferenciada na elaboração do resultado final [BALTZAKIS & PAPAMARKOS, 2000]. Em outros casos, é possível encontrar solução combinando um conjunto do mesmo tipo de classificador [BAJAJ & CHAUDHURY, 1996]. Muitas abordagens baseadas em características globais [DENG et al., 1999], [BAJAJ & CHAUDHURY, 1996] e [RIBEIRO & VASCONCELOS, 1999] demonstram ser mais rápidas no processo de extração de características, porém, de acordo com Justino [JUSTINO et at, 2002], métodos que utilizam características locais possuem capacidade discriminatória maior em relação à falsificações simuladas e simples.
Com relação à base de dados, muitos métodos apresentam quantidades de autores reduzidos para validação estatística [XIAO & LEEDHAM, 1999], [BAJAJ & CHAUDHURY, 1996] e [MURSHED et al., 1995]. Já a quantidade de assinaturas genuínas usada por autor, no processo de aprendizagem, representa um problema, caso o número extrapole uma quantidade maior do que os normalmente aplicados em sistemas atuais, e desta forma dificulta a sua aplicação prática [SANSONE & VENTO, 2000], [MURSHED et al., 1995], [HUANG & YAN, 1997] [SABOURIN & GENEST, 1994] e [JUSTINO et al., 2003].
Existem algumas abordagens que utilizam técnicas de geração de amostras artificiais automaticamente [XIAO & LEEDHAM, 1999] e [FAEZ et al., 1997], como também a geração artificial automática de amostras de falsificações [HUANG & YAN, 1997]. Neste caso, há controvérsias com relação à incorporação destes tipos de amostras no processo de verificação por não refletir a variação intrapessoal como também as eventuais falsificações do mundo real. Um caso extremo é o de Velez [VELEZ et al., 2003] que apresentam um método de geração de múltiplas assinaturas de cada indivíduo, baseado em uma assinatura correspondente. Neste processo, tenta-se emular a variação intrapessoal dentro das assinaturas de cada autor, as quais são aplicadas em diferentes combinações, usando para tanto uma assinatura original. Desta forma cada assinatura original gera 1936 padrões de assinaturas sintéticas.
Algumas abordagens utilizam um processo de redução da dimensionalidade do vetor de características como em Justino [JUSTINO, 2001] e Murshed [MURSHED et al., 1995]. Neste último, um processo de redução de dimensionalidade nas imagens ainda forma um vetor de saída com 768 posições como entrada para uma rede Fuzzy ARTMAP. Métodos que incorporam grids [XIAO & LEEDHAM, 1999] e [JUSTINO, 2001], de certa forma já aplicam um processo de redução da dimensionalidade das características. Outros como Drouhard [DROUHARD et al., 1994] acreditam que um classificador é mais eficiente se diminuir a dimensão do vetor de entrada (dados desnecessários) e a variação no vetor de entrada ser menos abrupta (dados com ruídos).
Porém, características de um grid, submetidas diretamente ao classificador sem um processo de redução da dimensionalidade dos vetores de características, são abordadas por Xiao e Leedham [XIAO & LEEDHAM, 1999]. Xiao e Leedham utilizam um grid de 9x8 com 4 primitivas totalizando 288 posições de entrada em uma rede MLP. Os resultados obtidos nas taxas de erros são: 9,2% de erro na taxa de falsa rejeição e 17% de erro na taxa de falsa aceitação. Já em Rasha [RASHA, 1994] a camada de entrada de uma rede MLP é composta de 5.600 neurônios correspondendo à própria imagem 160x35 pixels. Infelizmente não há uma maneira de determinar estes parâmetros, desde que eles são fortemente dependentes da aplicação.
Comentários Finais
Os trabalhos apresentados neste capítulo contribuem na elaboração do presente trabalho no que se refere ao tipo de abordagem empregada , escolha das características e classificadores. Desta forma é proposta uma abordagem local com características estáticas e pseudodinâmicas baseadas no uso de técnicas grafométricas e uma rede neural MLP como classificador. No capítulo seguinte é descrita toda a fundamentação metodológica aplicada na abordagem proposta.