Informática Básica - S.O.
Ti - Tecnologia da Informação
1 Introdução a sistemas operacionais
Para que o hardware ou parte física de um computador possa funcionar, faz-se necessário um conjunto de regras e ordens que coordenem todos os processos realizados. Tal conjunto é denominado software ou parte não material do sistema. Graças ao software (integrado por uma enorme quantidade de programas que interagem entre si) todos os recursos podem ser utilizados em qualquer sistema informatizado. Todo o conjunto de programas que compõem o software pode ser dividido em dois grupos bem diferenciados:
1. Software básico: conjunto de programas imprescindíveis para o funcionamento do sistema. (Drivers controladores de hardware)
2. Software aplicativo. Conjunto de programas a serem utilizados pelo usuário(Word, Internet Explorer, Paciência).
À esse software, dá-se o nome de Sistema Operacional.
O Sistema Operacional
O sistema operacional tem duas funções distintas: estender a máquina e gerenciar recursos.
Como máquina estendida, o sistema operacional oculta a ‘verdade’ do usuário sobre o hardware e apresenta uma visão simples e agradável. Ele evita, por exemplo, que o usuário tenha que gerenciar o HD para gravar dados, e apresenta uma interface orientada a arquivos simples, geralmente em estrutura de pastas e diretórios. O sistema operacional também é responsável por fornecer uma variedade de serviços que os programas podem obter usando instruções especiais conhecidas como chamadas ao sistema, isso sem que o usuário tenha que interagir diretamente com a máquina.
Como gerenciador de recursos, o sistema operacional controla de forma ordenada o uso dos dispositivos físicos entre os vários programas que competem por eles. Esse gerenciamento é feito através de compartilhamento no tempo e no espaço. Quando um dispositivo é compartilhado no tempo, cada programa ou usuário aguarda a sua vez de usar o recurso(Processador). Quando um dispositivo é compartilhado no espaço, cada programa ou usuário ocupa uma parte do recurso (Memória RAM).
A diversidade de sistemas operacionais
No topo da lista estão os sistemas operacionais para computadores de grande porte. Esses computadores exigem grande capacidade de recursos de entrada/saída de dados. Seus sistemas operacionais são orientados para o processamento simultâneo de muitos trabalhos (jobs). Eles oferecem normalmente três tipos de serviços: em lote, processamento de transações e tempo compartilhado. Um exemplo é o OS/360.
Um nível abaixo estão os sistemas operacionais de servidores. Eles são executados em servidores, em estações de trabalho ou em computadores de grande porte. Eles servem múltiplos usuários de uma vez em uma rede e permitem-lhes compartilhar recursos de hardware e software. Exemplos incluem Linux e Windows 2003 Server.
Há também os sistemas operacionais de multiprocessadores. Esse sistema consiste em conectar várias CPUs em um único sistema para ganhar potência computacional. Eles usam variações dos sistemas operacionais de servidores com aspectos especiais de comunicação e conectividade.
O nível seguinte é o sistema de computadores pessoais. Sua função é oferecer uma boa interface para um único usuário. Exemplos comuns são o Windows Vista e XP, o MacOS e o Linux.
O próximo nível é o de sistemas de tempo real. O tempo é um parâmetro fundamental. Eles são divididos em sistemas de tempo real crítico e de tempo real não crítico. Os sistemas de tempo real crítico possuem determinados instantes em que as ações devem ocorrer. Os sistemas de tempo real não crítico aceita um descumprimento ocasional de um prazo. VxWorks e QNX são exemplos bem conhecidos.
Descendo na escala, vemos os sistemas operacionais móveis e embarcados. Os sistemas móveis estão presentes em computadores de mão que são computadores muito pequenos que realizam funções de agenda e livro de endereços. Os sistemas embarcados são computadores que controlam eletrodomésticos ou sistemas de comunicação e de orientação por gps em veículos. Exemplos de sistemas operacionais móveis são o PalmOS e o Windows Mobile. De sistema operacional embarcado pode-se citar o Microsoft SYNC e o sistema de GPS do Fiat Linea.
Os menores sistemas operacionais são executados em cartões inteligentes. São dispositivos do tamanho de cartões de crédito que contêm uma CPU. Possuem restrições severas de consumo de energia e memória. Alguns são orientados a Java. Um exemplo é o SmartCard da Athos Sistemas do Brasil, utilizado em sistemas de controle de acesso e gerenciamento de estoques.
Exemplos de sistemas operacionais comuns.
● Microsoft Windows Vista e XP – Sistema operacional para estações de trabalho, sejam elas domésticas ou em ambiente corporativo.
● Microsoft Windows Server 2003 – Sistema operacional para servidores, com recursos para gerenciamento de usuários e estações de trabalho.
● Linux (CentOS, Fedora, Debian, Suse, Slackware, Kurumin)– Sistema operacional utilizado tanto em servidores quanto estações de trabalho. Possui uma ampla disponibilidade de aplicativos compatíveis, como servidores de rede, aplicativos multimídia, entre outros.
A história dos sistemas operacionais.
Os sistemas operacionais têm sido historicamente amarrados à arquitetura dos computadores nos quais iriam rodar. Por isso, veremos como eles evoluíram nas sucessivas gerações de computadores. Esse mapeamento entre gerações de computadores e gerações de sistemas operacionais é admissivelmente imaturo, mas tem algum sentido.
O primeiro computador digital verdadeiro foi projetado pelo matemático inglês Charles Babbage (1792-1871). Embora Babbage tenha dispendido muito de sua vida e de sua fortuna tentando construir sua "máquina analítica", ele jamais conseguiu por o seu projeto em funcionamento porque era simplesmente um modelo matemático e a tecnologia da época não era capaz de produzir rodas, engrenagens, dentes e outras partes mecânicas para a alta precisão que necessitava. Desnecessário se dizer que a máquina analítica não teve um sistema operacional.
2 Conceitos sobre sistemas operacionais
Processos
Processo, no contexto da informática, é um programa de computador em execução.
Em sistemas operacionais, processo é um módulo executável único, que corre concorrentemente com outros módulos executáveis. Por exemplo, em um ambiente multi-tarefa (como o Unix) que suporta processos, um processador de texto, um navegador e um sistema de banco de dados são processos separados que podem rodar concomitantemente. Processos são módulos separados e carregáveis, ao contrário de threads, que não podem ser carregadas. Múltiplas threads de execução podem ocorrer dentro de um mesmo processo. Além das threads, o processo também inclui certos recursos, como arquivos e alocações dinâmicas de memória e espaços de endereçamento.
A comunicação entre processos é o grupo de mecanismos que permite aos processos transferirem informação entre si. A capacidade de um sistema operacional executar simultaneamente dois ou mais processos é chamada multiprocessamento. Se existirem dois ou mais processos executados em simultâneo e disputam o acesso a recursos partilhados, problemas da concorrência podem ocorrer. Estes problemas podem ser resolvidos pelo gerenciamento adequado de múltiplas linhas de execução ou processos através da sincronização (multitarefa) ou por outros recursos (como a troca de contexto).
Estados de processos
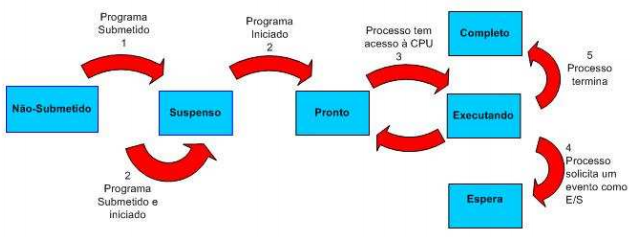
Estado 1 - Não-Submetido
É o processo que ainda não está submetido a CPU, está nas mãos do usuário." Até onde interessa ao sistemas ele não existe, porque o usuário ainda não o submeteu. Ele é simplesmente apresentado como sendo o primeiro passo na vida de um processo. O Sistema Operacional, naturalmente, não reconhece esse estado.[1]". Pode por exemplo, ser um arquivo executável que está armazenado no HD.
Estado 2 - Suspenso
É o processo que já foi submetido, porém permanece suspenso até que o horário ou evento programado ao usuário venha acontecer. Temos como exemplo o agendamento de uma varredura programada no anti-vírus por um usuário.
Estado 3 - Pronto
O processo já foi submetido e está pronto para receber a CPU, porém ainda guarda o escalonador de processos para ter controle da CPU. Processos que estão esperando E/S não se aplicam a esse estado.
Estado 4 - Executando
A execução propriamente dita. O código está sendo processado. Se ocorrer durante a execução uma requisição de E/S o processo é colocado no estado de espera e outro processo da fila de prontos poderá então concorrer a CPU.
Estado 5 - Espera
É o processo que foi colocado na fila de espera de E/S devido ao processador de E/S ser mais lento que a CPU principal. O processo tornaria a CPU mais escrava dele se não houvesse esse estado, pois como ele não está concorrendo à CPU ao executar um E/S, pode-se então colocá-lo no estado de espera para que os demais processos do estado pronto possam concorrer a CPU.
Ex: parte de um código em C
scanf(“%d”, VALOR);
SOMA=VALOR+JUROS;
Como podemos notar, a instrução scanf (uma requisição de entrada e saída) é gerada se não fosse possível colocar o processo em estado de espera; caso o usuário não entrasse com nenhum valor, o programa ficaria suspenso e não liberaria a CPU para outros processos.
Estado 6 - Completo
Neste estado temos a finalização do processo.
Threads
Da mesma forma que os processos sofrem escalonamento as threads também tem a mesma necessidade. O escalonamento de threads é variável dependendo do tipo da thread que são Kernel-Level Thread e User-Level Thread. Da mesma forma que quando vários processos são executados em apenas uma CPU eles sofrem escalonamento e parecem que todos são executados ao mesmo tempo, quando um processo tem threads elas esperam a sua vez para ser executadas, como esta alternância é muito rápida há impressão de que todos os processos e as thread destes processos são executadas paralelamente.
Geralmente quando iniciamos um processo com múltiplas threads existe um thread principal que é responsável por gerenciar criar novas threads , quando uma thread finaliza seu trabalho ela entra em thread_yield, que sinaliza que a thread encerrou seu trabalho e esta liberando a CPU para outra thread ou processo.
User-Level Thread
As ULT(User-Level Thread) são escalonadas pelo programador, tendo a grande vantagem de cada processo ter como usar um algoritmo de escalonamento que melhor se adapte a situação, o SO não tem a obrigação de fazer o escalonamento destas threads, em geral ele nem sabe que as threads existem, estas threads são geralmente mais rápidas que as KLT, pois dispensam a chamada ao SO para escalonar evitando assim uma mudança total de contexto do processador memória e diversas outros níveis para alternar os processos. Neste modo o programador é responsável por criar, executar, escalonar e destruir a thread. Vamos a um exemplo prático, um processo chamado P1, este processo pode ter varias threads, neste exemplo ele tem P1T1, P1T2, P1T3, então quando o SO da o CPU para o processo P1 cabe a ele destinar qual thread será executada, caso esta thread use todo processo do quantum, o SO chamara outro processo, e quando o processo P1 voltar a executar P1T1 voltará a ser executada e continuará executando até seu término ou intervenção de P1, este comportamento não afetará outros processos pois o SO continua escalonando os processos normalmente.
Kernel-Level Thread
As KLT são escalonadas diretamente pelo SO, comumente são mais lentas que as Threads ULT pois a cada chamada elas necessitam consultar o SO, exigindo assim a mudança total do contexto do processador memória e outros níveis necessários para alternar um processo. Vamos citar outro exemplo pratico, um processo chamado P2 com as threads P2T1, P2T2, P2T3, e outro processo chamado P3 com as threads P3T1, P3T2, P3T3. SO não entregara a CPU ao processo e sim a uma thread deste processo, note agora que o SO é responsável por escalonar as threads e este SO tem que suportar Threads, a cada interupção de thread é necessário mudar todo o contexto de CPU e memória porém as threads são independentes dos processos, podemos executar então P3T2, P2T1, P2T2, P2T1, P3T1,P2T3,P3T3, ou seja a ordem em que o escalonador do SO determinar.
Já com as threads em modo usuário não conseguimos ter a mesma independência, pois quando passamos o controle ao processo enquanto seu quantum for válido ele irá decidir que thread irá rodar. Um escalonamento típico do SO é onde o escalonador sempre escolhe a thread de maior prioridade, que são divididas em duas classes que são Real Time e Normal, cada thread ganha uma prioridade ao ser criada que varia de 0 a 31(0 é a menor e 31 maior), processos com prioridade 0 a 15(Real Time) tem prioridade ajustada no tempo de execução como nos processos de E/S que tem a prioridade aumentada variando o periférico, processos com prioridade 16 a 31 são executados até terminar e não tem prioridade alterada, mas somente uma thread recebe a prioridade zero que é a responsável por zerar páginas livres no sistema. Existe ainda uma outra classe chamada de idle, uma classe mais baixa ainda, só é executada quando não existem threads aptas, threads dessa classe não interferem na performance.
Deadlocks
Deadlock (blocagem, impasse), no contexto do sistemas operacionais (SO), caracteriza uma situação em que ocorre um impasse e dois ou mais processos ficam impedidos de continuar suas execuções, ou seja, ficam bloqueados. Trata-se de um problema bastante estudado no contexto dos Sistemas Operacionais, assim como em outras disciplinas, como banco de dados, pois é inerente à própria natureza desses sistemas.
O deadlock ocorre com um conjunto de processos e recursos não-preemptíveis, onde um ou mais processos desse conjunto está aguardando a liberação de um recurso por um outro processo que, por sua vez, aguarda a liberação de outro recurso alocado ou dependente do primeiro processo.
A definição textual de deadlock normalmente, por ser muito abstrata, é mais difícil de se compreender do que a representação por grafos, que será resumida mais adiante. No entanto, algumas observações são pertinentes:
A definição textual de deadlock normalmente, por ser muito abstrata, é mais difícil de se compreender do que a representação por grafos, que será resumida mais adiante. No entanto, algumas observações são pertinentes:
• O deadlock pode ocorrer mesmo que haja somente um processo no SO, considerando que este processo utilize múltiplos threads e que tais threads requisitem os recursos alocados a outros threads no mesmo processo;
• O deadlock independe da quantidade de recursos disponíveis no sistema;
• Normalmente o deadlock ocorre com recursos como dispositivos, arquivos, memória etc. Apesar da CPU também ser um recurso para o SO, em geral é um recurso facilmente preemptível, pois existem os escalonadores para compartilhar o processador entre os diversos processos, quando trata-se de um ambiente multitarefa.
Um exemplo onde erros de deadlock ocorrem é no banco de dados. Suponha que uma empresa tenha vários vendedores e vários pontos de venda/caixas. O vendedor A vendeu 1 martelo e 1 furadeira. O sistema então solicita o travamento do registro da tabela ESTOQUE que contém o total de martelos em estoque e em seguida solicita o travamento do registro que contém o total de furadeiras em estoque. De posse da exclusividade de acesso aos dois registros, ele lê a quantidade de martelos, subtrai 1 e escreve de novo no registro, o mesmo com o registro de furadeiras.
Observe, no entanto que existem diversos caixas operando simultaneamente de forma que se algum outro caixa naquele exato instante estiver vendendo um furadeira, ele ficará de aguardando a liberação do registro das furadeiras para depois alterá-lo. Note que ele só altera os registro depois que for dada exclusividade para ele de TODOS os recursos que ele precisa, ou seja, de todos os registro. Suponha agora que em outro caixa a venda foram vendidos 1 furadeira e 1 martelo e que o outro caixa solicitou o travamento do registro com a quantidade de furadeiras e agora quer o acesso ao de martelos, no entanto o de martelos está travado para o primeiro caixa. Nenhum deles devolve o recurso (registro) sobre o qual tem exclusividade e também não consegue acesso ao outro registro que falta para terminar a operação. Isto é um deadlock.
Condições necessárias para a ocorrência de deadlock.
No texto acima, foi dito que o deadlock ocorre naturalmente em alguns sistemas. No entanto, é necessário ressaltar que tais sistemas precisam obedecer a algumas condições para que uma situação de deadlock se manifeste.
Essas condições estão listadas abaixo, onde as três primeiras caracterizam um modelo de sistema, e a última é o deadlock propriamente dito: processos que estejam de posse de recursos obtidos anteriormente podem solicitar novos recursos. Caso estes recursos já estejam alocados a outros processos, o processo solicitante deve aguardar pela liberação do mesmo;
• Condição de não-preempção: recursos já alocados a processos não podem ser tomados a força. Eles precisam ser liberados explicitamente pelo processo que detém a sua posse;
• Condição de espera circular: deve existir uma cadeia circular de dois ou mais processos, cada um dos quais esperando por um recurso que está com o próximo membro da cadeia.
• Condição de exclusão mútua: cada recurso ou está alocado a exatamente um processo ou está disponível;
• Condição de posse-e-espera: cada processo pode solicitar um recurso, ter esse recurso alocado para si e ficar bloqueado esperando por um outro recurso;
3 Representação de deadlock em grafos
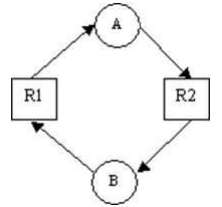
Exemplo de representação de deadlock em grafos de alocação de recursos, com dois processos A e B, e dois recursos R1 e R2.
O deadlock também pode ser representado na forma de grafos dirigidos, onde o processo é representado por um círculo e o recurso, por um quadrado. Quando um processo solicita um recurso, uma seta é dirigida do círculo ao quadrado. Quando um recurso é alocado a um processo, uma seta é dirigida do quadrado ao círculo.
Na figura do exemplo, podem-se ver dois processos diferentes (A e B), cada um com um recurso diferente alocado (R1 e R2). Nesse exemplo clássico de deadlock, é facilmente visível a condição de espera circular em que os processos se encontram, onde cada um solicita o recurso que está alocado ao outro processo.
Tratamento de deadlock
As situações de deadlock podem ser tratadas ou não em um sistema, e cabe aos desenvolvedores avaliar o custo/benefício que essas implementações podem trazer. Normalmente, as estratégias usadas para detectar e tratar as situações de deadlocks geram grande sobrecarga, podendo até causar um dano maior que a própria ocorrência do deadlock, sendo, às vezes, melhor ignorar a situação.
Existem três estratégias para tratamento de deadlocks:
• Ignorar a situação;
• Detectar o deadlock e recuperar o sistema; e
• Evitar o deadlock;
Algoritmo do Avestruz (Ignorar a situação)
A estratégia mais simples para tratamento (ou não) do deadlock, conhecida como Algoritmo do Avestruz, é simplesmente ignorá-lo. Muitos defendem que a frequência de ocorrência deste tipo de evento é baixa demais para que seja necessário sobrecarregar a CPU com códigos extras de tratamento, e que, ocasionalmente, é tolerável reiniciar o sistema como uma ação corretiva.
Detectar o deadlock e recuperar o sistema
Nessa estratégia, o sistema permite que ocorra o deadlock e só então executa o procedimento de recuperação, que resume-se na detecção da ocorrência e na recuperação posterior do sistema. É na execução desse procedimento que ocorre a sobrecarga, pois existem dois grandes problemas: primeiramente, como/quando detectar o deadlock e depois, como corrigi-lo. Para detectar o deadlock, o sistema deve implementar uma estrutura de dados que armazene as informações sobre os processos e os recursos alocados a eles. Essas estruturas deverão ser atualizadas dinamicamente, de modo que reflitam realmente a situação de cada processo/recurso no sistema.
Só o mero procedimento de atualização dessas estruturas já gera uma sobrecarga no sistema, pois toda vez que um processo aloca, libera ou requisita um recurso, as estruturas precisam ser atualizadas. Além disso, o SO precisa verificar a ocorrência da condição de espera circular nessas estruturas para a efetiva detecção do deadlock. Esse procedimento, por sua vez, gera outra sobrecarga, que pode ser mais intensa se não for definido um evento em particular para ser executado, como a liberação de um recurso, por exemplo. Assim, ou o SO verifica periodicamente as estruturas (o que não é aconselhável, pois pode aumentar consideravelmente o tempo de espera dos processos não-bloqueados), ou pode-se implementar uma política, onde o SO verifica as estruturas quando o mesmo realizar algum procedimento de manutenção do sistema, por exemplo.
Finalmente, só após detectar a presença do deadlock no sistema, o SO precisa corrigi-lo, executando um procedimento de recuperação. Quanto à detecção do deadlock, vamos apresentar uma das técnicas usadas para detectar a ocorrência de deadlock em sistemas que possuem vários recursos de cada tipo.
Detecção de deadlock com vários recursos de cada tipo
O algoritmo de detecção de deadlock com vários recursos de cada tipo baseia-se em um ambiente que possua vários recursos do mesmo tipo e os processos solicitam apenas pelo tipo de recursos, não especificando qual recurso desejam utilizar. Assim, um processo pode requisitar uma unidade de CD para leitura. Se o sistema possuir duas, o processo pode utilizar a que estiver disponível, em vez de especificar uma delas. Dessa forma, o processo solicita o recurso pelo tipo, sem discriminação.
O algoritmo para essa detecção trabalha com duas variáveis, três matrizes unidimensionais (vetores) e duas matrizes bidimensionais, descritas a seguir:
• Estruturas:

Faça (para preenchimento das estruturas):
1. Preencher a Matriz E com as quantidade de instâncias de cada tipo de recurso;
2. Preencher a Matriz C com as quantidade de instâncias de cada tipo alocadas aos processos, sendo que a somatória de cada coluna da Matriz C deve ser menor ou igual à quantidade do recurso correspondente na Matriz E (os processos nunca podem requisitar mais recursos que existentes no sistema);
3. Preencher a Matriz W com o resultado da subtração da quantidade de cada recurso da Matriz E com o valor do somatório de cada coluna do recurso correspondente da Matriz C, ou seja:
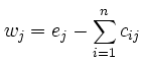
4. Preencher inicialmente a Matriz A com os valores da Matriz W. Note que:
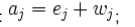
5. Preencher a Matriz R com as próximas requisições dos processos, seguindo as mesmas regras da Matriz C.
Faça (para detecção do deadlock):
1. Inicialmente, desmarcar todos os processos;
2. Para um processo Pi desmarcado, verificar se todos os elementos da linha i na Matriz R são menores ou iguais aos da Matriz A;
3. Se for, então marque o execute o processo Pi e libere os recursos requisitados pelo processo na Matriz C (adicionar a linha i da Matriz C na Matriz A);
4. Retornar ao passo 2.
A lógica do algoritmo é a seguinte: cada processo é considerado como apto a ser executado até que a detecção prove o contrário. A detecção apenas verifica se os processos requisitam mais recursos do que estão disponíveis, o que caracteriza um deadlock. Caso o processo requisite uma quantidade disponível, então ele pode ser executado, e os recursos que foram solicitados antes podem também ser liberados de volta ao sistema, o que pode permitir que outros processos também concluam suas execuções e liberem os recursos.
Um exemplo do preenchimento das matrizes encontra-se na figura abaixo, considerando-se n=2 e m=3.
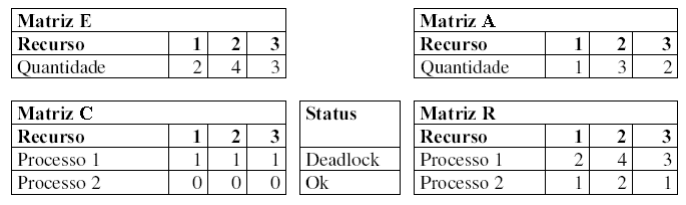
Exemplo do preenchimento das matrizes do algoritmo de detecção de deadlock com vários recursos de cada tipo.
4 Gerenciamento de memória
Gerenciamento de memória é um complexo campo da ciência da computação e são constantemente desenvolvidas várias técnicas para torná-la mais eficiente. Em sua forma mais simples, está relacionado em duas tarefas essenciais:
• Alocação: Quando o programa requisita um bloco de memória, o gerenciador o disponibiliza para a alocação;
• Reciclagem: Quando um bloco de memória foi alocado, mas os dados não foram requisitados por um determinado numero de ciclos, esse é liberado e pode ser reutilizado para outra requisição.
Gerência de Memória
A cada dia que passa os programadores necessitam de mais memória e mais programas rodando simultaneamente para poderem tratar cada vez mais informações. O tratamento necessário da memória utilizada não é uma tarefa fácil de ser implementada. Existem vários requisitos que devem ser observados para o correto funcionamento, tais como, Segurança, Isolamento, Performance, entre outros. Para isto a função de gerenciar a memória passa a ser do sistema operacional e não mais do aplicativo.
Alocação
A alocação de memória pode ser:
• Alocação estática: Decisão tomada quando o programa é compilado.
• Alocação dinâmica: Decisão é adiada até a execução. (Permite swapping)
Fragmentação
Desperdício de páginas de memória alocadas Pode ser de dois tipos: interna e externa. Interna: Ocorre quando o processo não ocupa inteiramente os blocos de memória (páginas) reservados para ele. Geralmente acontece pois o tamanho do processo não é um múltiplo do tamanho da página de memória, o que acarreta sobra de espaço na última página alocada.
Externa: Ocorre à medida que os programas vão terminando e deixando lacunas cada vez menores de espaços, o que os torna inutilizáveis. Estratégias para “atacar” o problema com o algoritmos First-fit, Best-fit, Worstfit e Next-fit
Paginação
“Quebra” a memória do processo permitindo espaços de endereçamento não contíguos.
TLB
A Translation Lookaside Buffer (TLB) é um conjunto de registradores especiais que são super rápidos. Cada registrador tem duas partes: chave e valor. Dada uma chave, busca-se o valor correspondente. Geralmente, 64 entradas, no máximo, e a busca é feita em todos os registradores simultaneamente.
Memória Virtual é uma técnica poderosa e sofisticada de gerência de memória, onde as memórias principal e secudária são combinadas, dando ao usuário a ilusão de existir uma memória muito maior que a capacidade real da memória principal. O conceito desta técnica fundamenta-se em não vincular o endereçamento feito pelo programa aos endereços físicos da memória principal. Desta forma, programas e suas estruturas de dados deixam de estar limitados ao tamanho da memória física disponível, pois podem possuir endereços associados à memória secundária.
Algoritmos de Substituição de Página
• Algoritmo Ótimo
• Algoritmo Não Usada Recentemente
• Algoritmo FIFO
• Algoritmo Segunda Chance
• Algoritmo do relógio
• Menos Recentemente Usada
• WSClock
Gerenciamento manual de memória
Em modelos de gerenciamento manual, podem ocorrer os problemas conhecidos como vazamento de memória, que acontece quando uma quantidade de memória é alocada e não é liberada ainda que nunca seja utilizada. Isto ocorre quando objetos perdem a referência sem terem sido liberados, mantendo o uso do espaço de memória.
Garbage Collector
É o gerenciamento automático de memória, também conhecido como coletores, sendo conhecido em Portugal como reciclagem automática de memória. Este serviço libera os blocos de memória que não sejam mais usados por um programa automaticamente.
As vantagens desse tipo de gerenciamento são:
• Liberdade do programador: Não é obrigado ficar atento aos detalhes da memória;
• Menos bugs de gerenciamento de memória: Por se tratar de uma técnica mais confiável;
• Gerenciamento automático: Mais eficiente que o manual;
E entre as desvantagens, podemos citar:
• O desenvolvedor tende a estar mais desatento em relação a detalhes de memória;
• O gerenciador automático ainda apresenta limitações.
Quando deixam de existir referências a um objeto, este passa a ser considerado apto a ser "coletado" pelo garbage collector, que significa dizer que será removido da memória, deixando-a livre para uso por outros objetos.
Os algoritmos de garbage collection operam de um modo que permite classificá-los em duas grandes famílias:
• identificação directa: por contagem de referências (reference counting);
• identificação indirecta: por varrimento (tracing), que pode incluir também compactação da memória livre; cópia; ou geracional (utilizado nas máquinas virtuais Java e .Net)
Gerenciamento de memória no DOS
O IBM PC original foi projetado com uma memória RAM de 1024KB
• 640KB o Para o sistema operacional e programas
• 384KB - área de memória superior (Upper Memory Area) ou UMA o Para os adaptadores diversos como EGA & VGA, MDA, adaptadores CGA, e de redes. o ROM BIOS e Shadow RAM. o E mais tarde, área de paginação de expansão de memória (EMS) vista mais adiante.
Logo depois, foi provado que esta quantidade de memória se tornaria insuficiente para as necessidades futuras. Entretanto, os sistemas operacionais e aplicativos desenvolvidos até então não seriam capazes de reconhecer um endereço de memória superior aos 640KB originais, o que levou os projetistas a desenvolverem ferramentas que executariam esta tarefa.